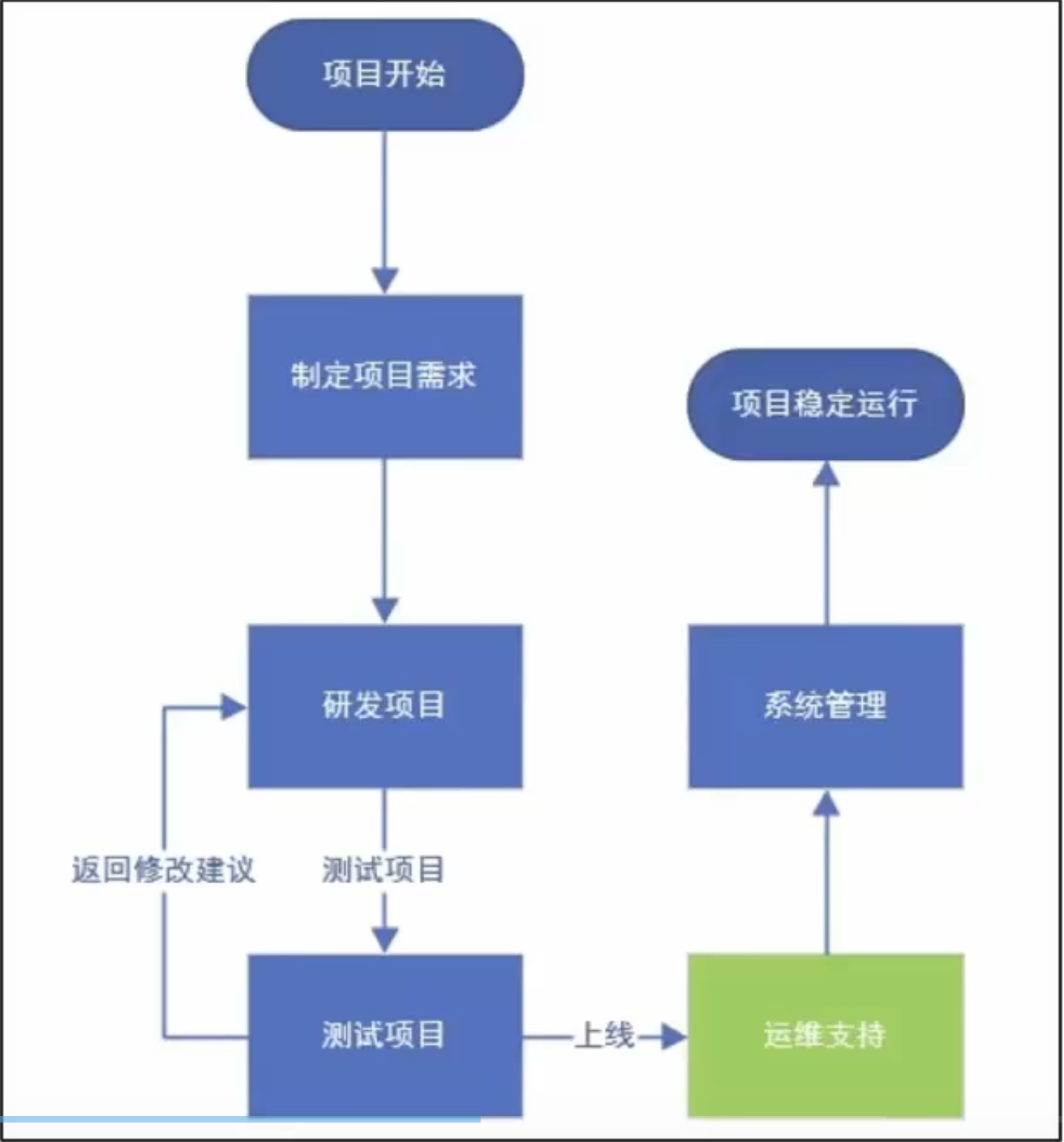
1.GPU云服务器
1.1 部署说明
本次聊天机器人底座采用ChatGLM-6B模型,ChatGLM是由清华大学与智谱A[联合开发的开源双语对话语言模型,基于GLM(General Language Model)架构,支持中英双语交互,尤其针对中文场景优化。其代表版本ChatGLM-6B具备60亿参数,融合监督微调、人类反馈强化学习等技术,适用于金融、营销、公共服务等多领域智能化应用。
部署该模型服务器要求: 操作系统:Linux 显存(GPU):最低4GB 建议8GB以上 内存:大于等于8GBCPU:大于等于4核 磁盘空间:建议大于40GB
1.2 申领服务器
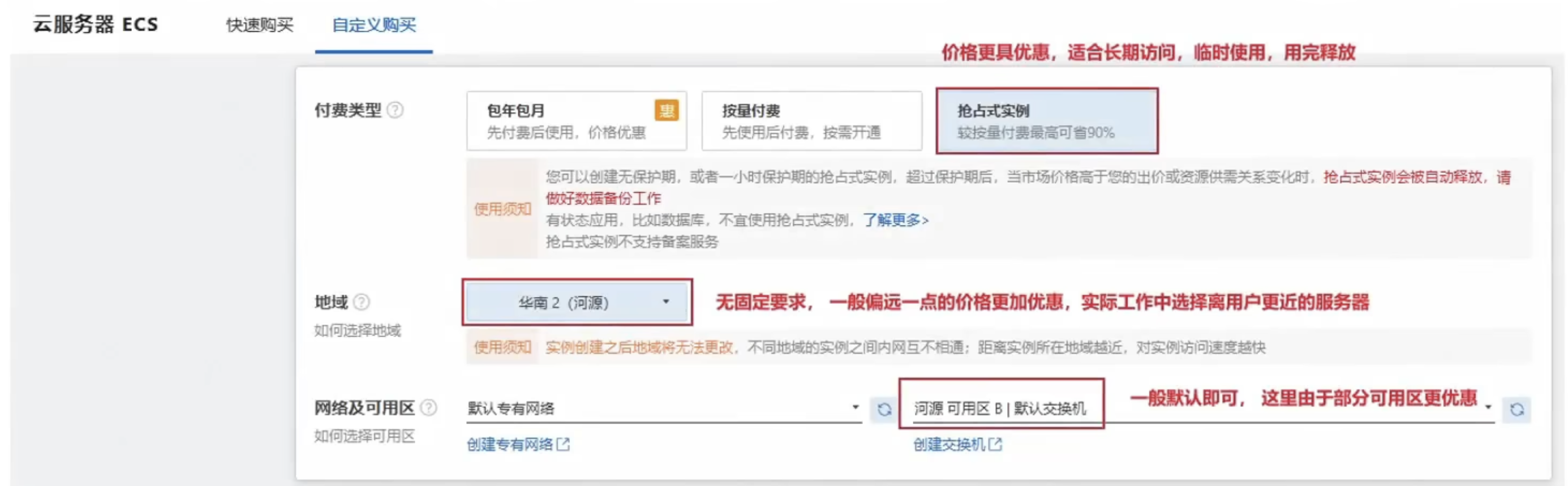
选择实例与镜像:
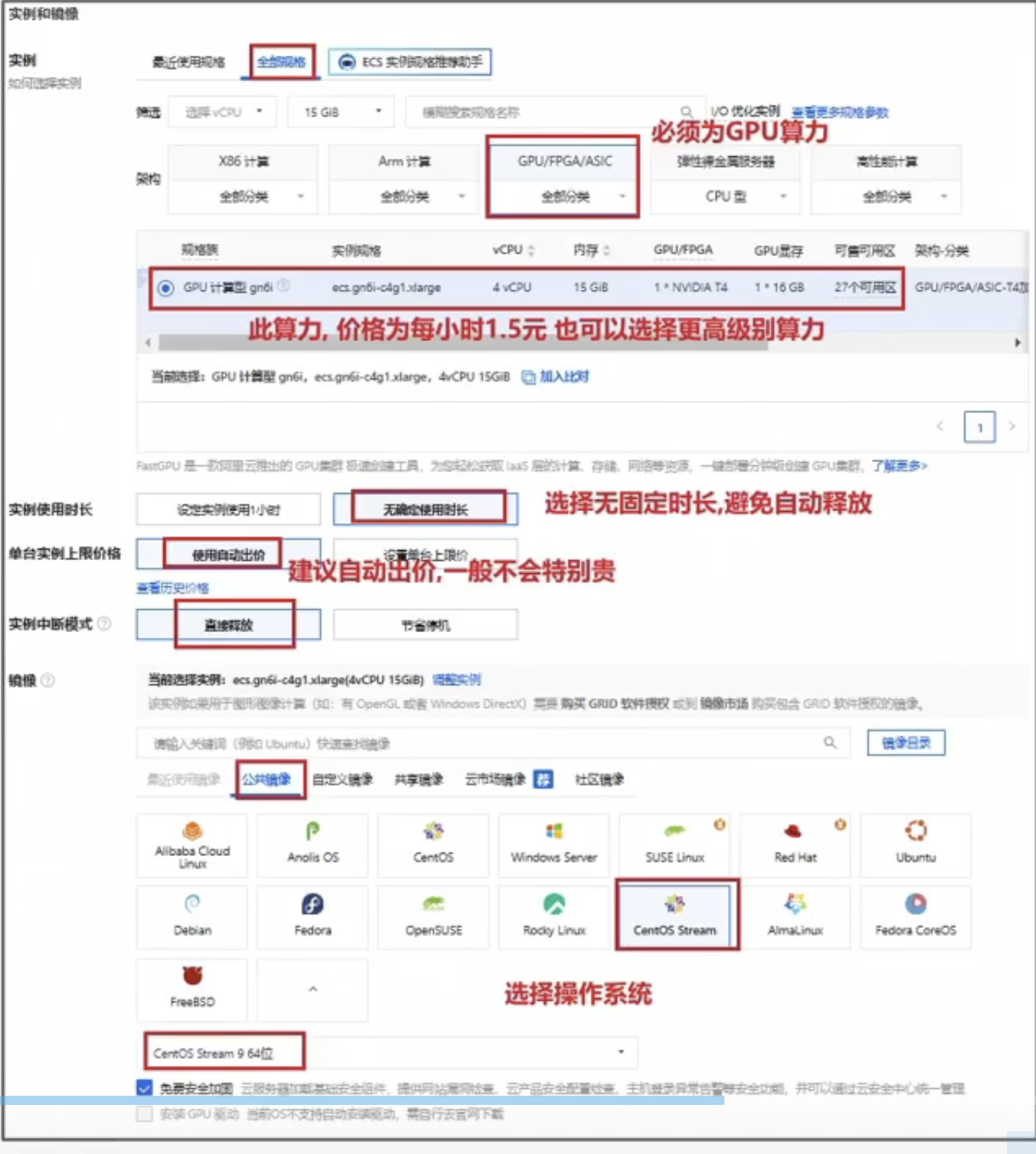
然后连接服务器
1.3 安装GPU驱动
第一步:验证服务器是否安装显卡驱动:
查看显卡信息:
lspci | grep -i nvidia

运行以下命令验证驱动是否正确加载:
nvidia-smi

第二步:下载驱动 根据查看得显卡,得知为NVIDIA显卡 下载该显卡的开发版本相关驱动: https://developer.nvidia.com/cuda-downloads
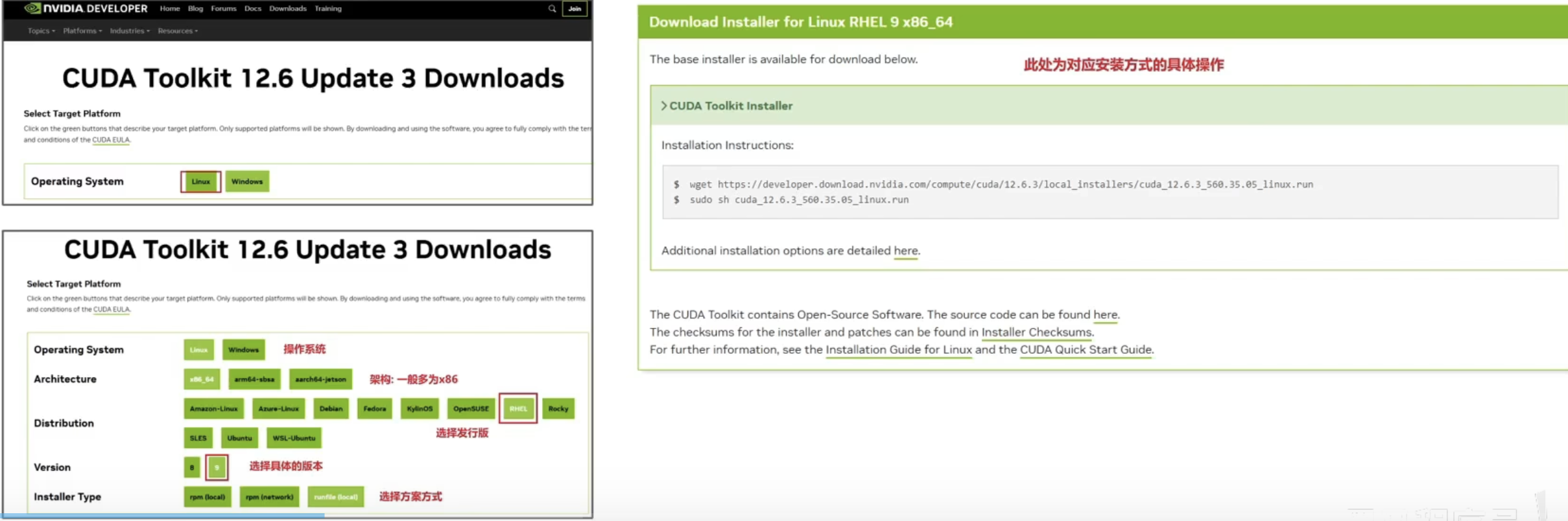
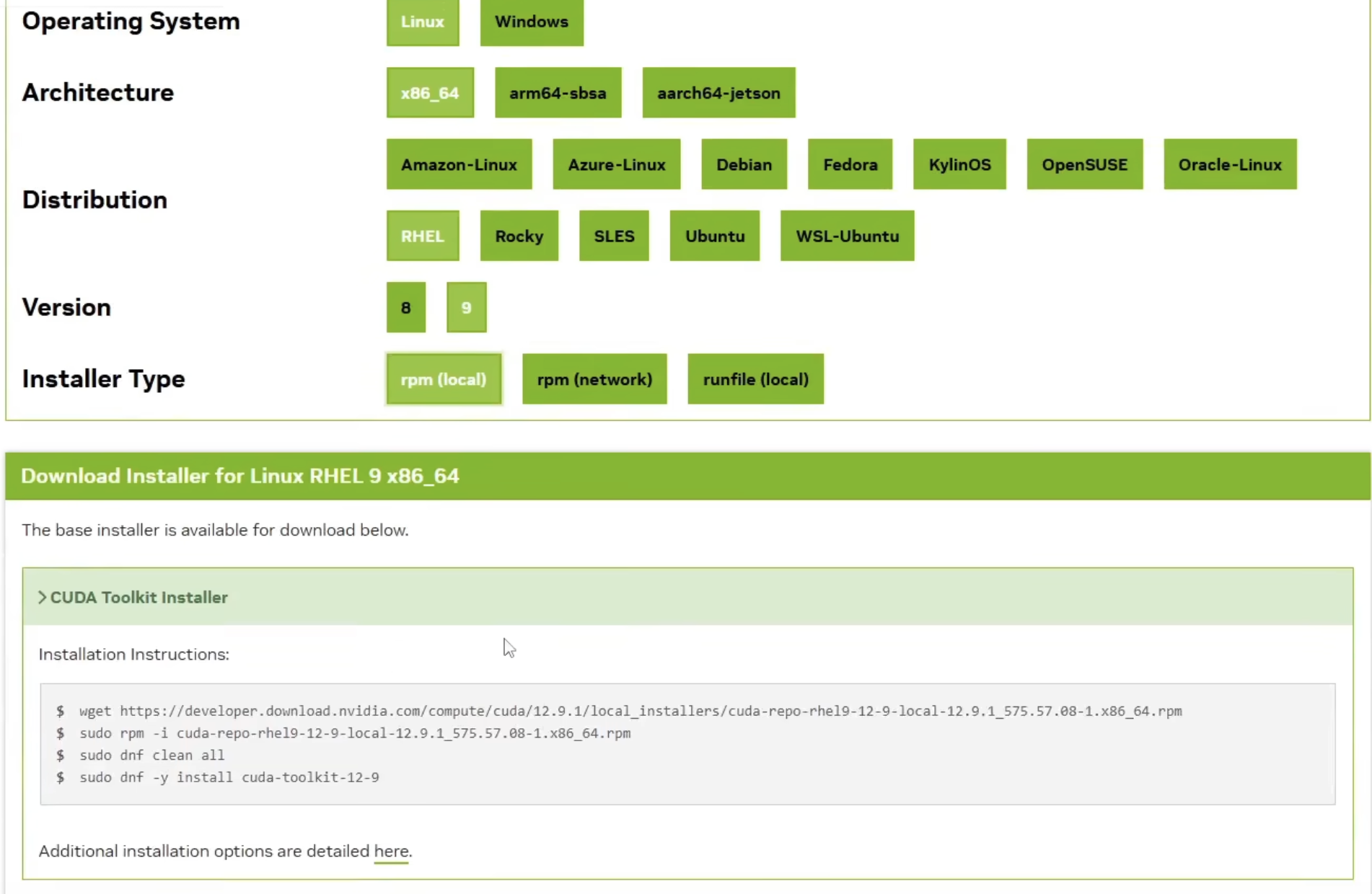
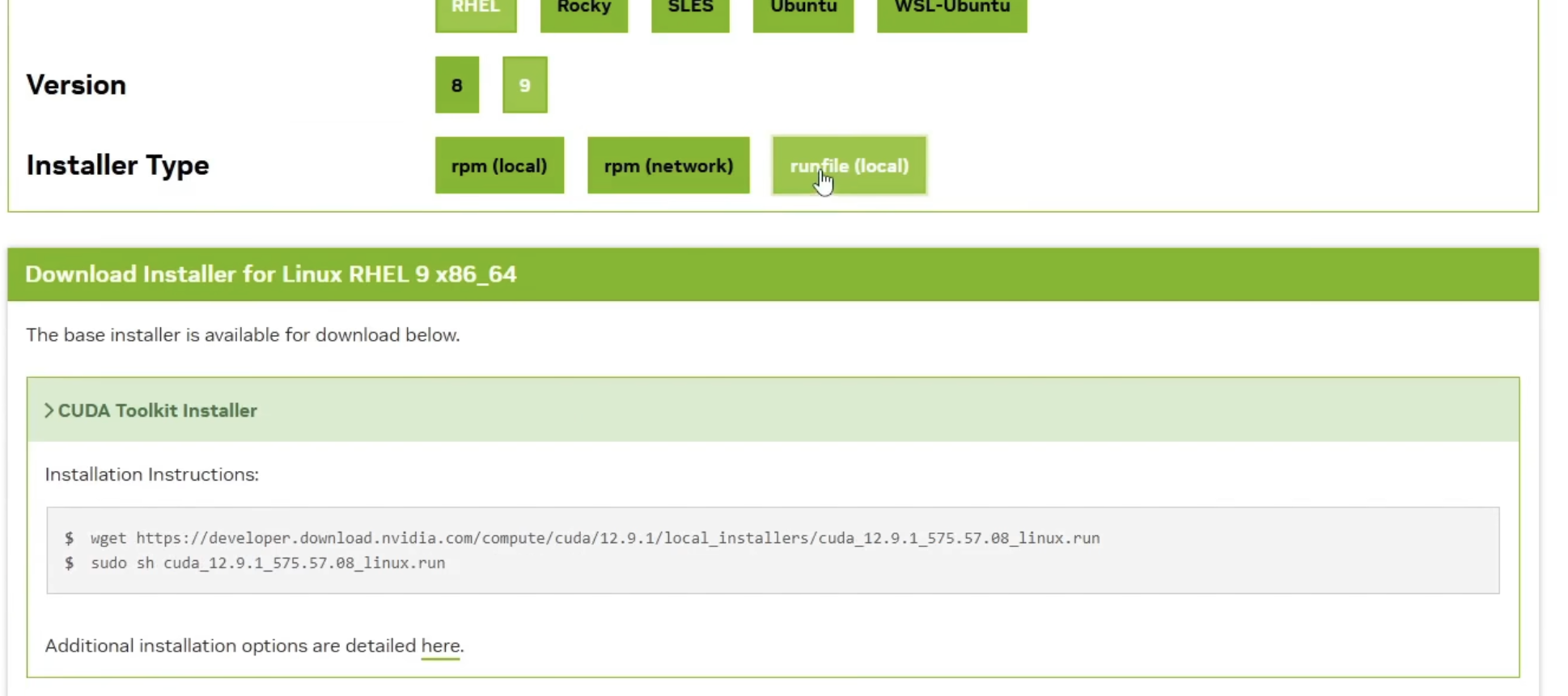
下载:
cd~
wget https://developer.download.nvidia.com/compute/cuda/12.6.3/local_installers/cuda_12.6.3_560.35.05_linux.run
执行安装:
sh cuda_12.6.3_560.35.05_linux.run

第三步:添加环境变量
#添加CUDA驱动
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
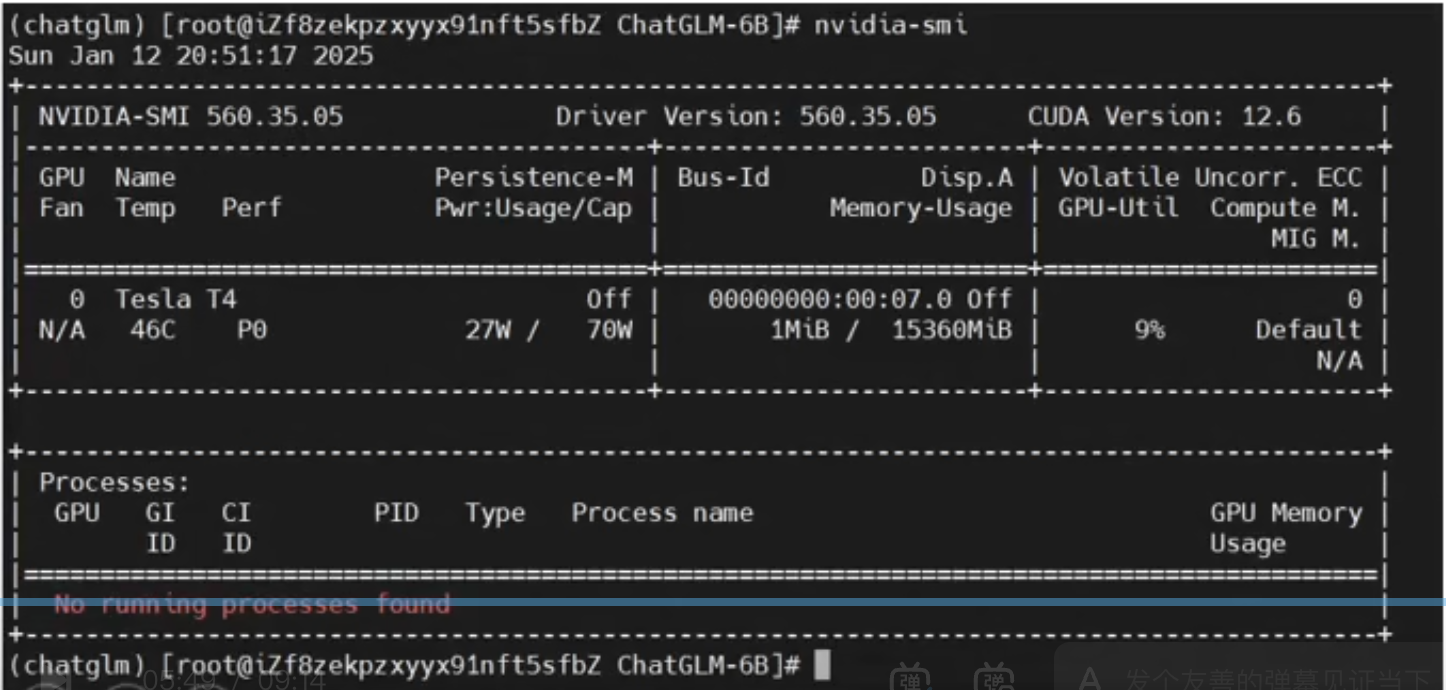
校验:
nvidia-smi
2. 基础环境安装
由于本次基于chatglm-6b大模型部署,采用的Python语言开发的,使用大量的Python核心库,顾首先需要再服务器中安装Python环境。
本次采用安装Anaconda来安装,Anaconda是一款开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项,同时Anaconda还提供虚拟环境,支持隔离不同的Python环境,从而减少互相影响。故一般部署Python项目主要安装以Anaconda版本为主。
第一步:下载Anaconda
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh

第二步:安装Anaconda
bash Anaconda3-2024.10-1-Linux-x86_64.sh
注意:如果没有跳出询问初始化的界面,该怎么办?
cd~ #如果你不是root用户,切换到自己的家目录下
vim .bashrc
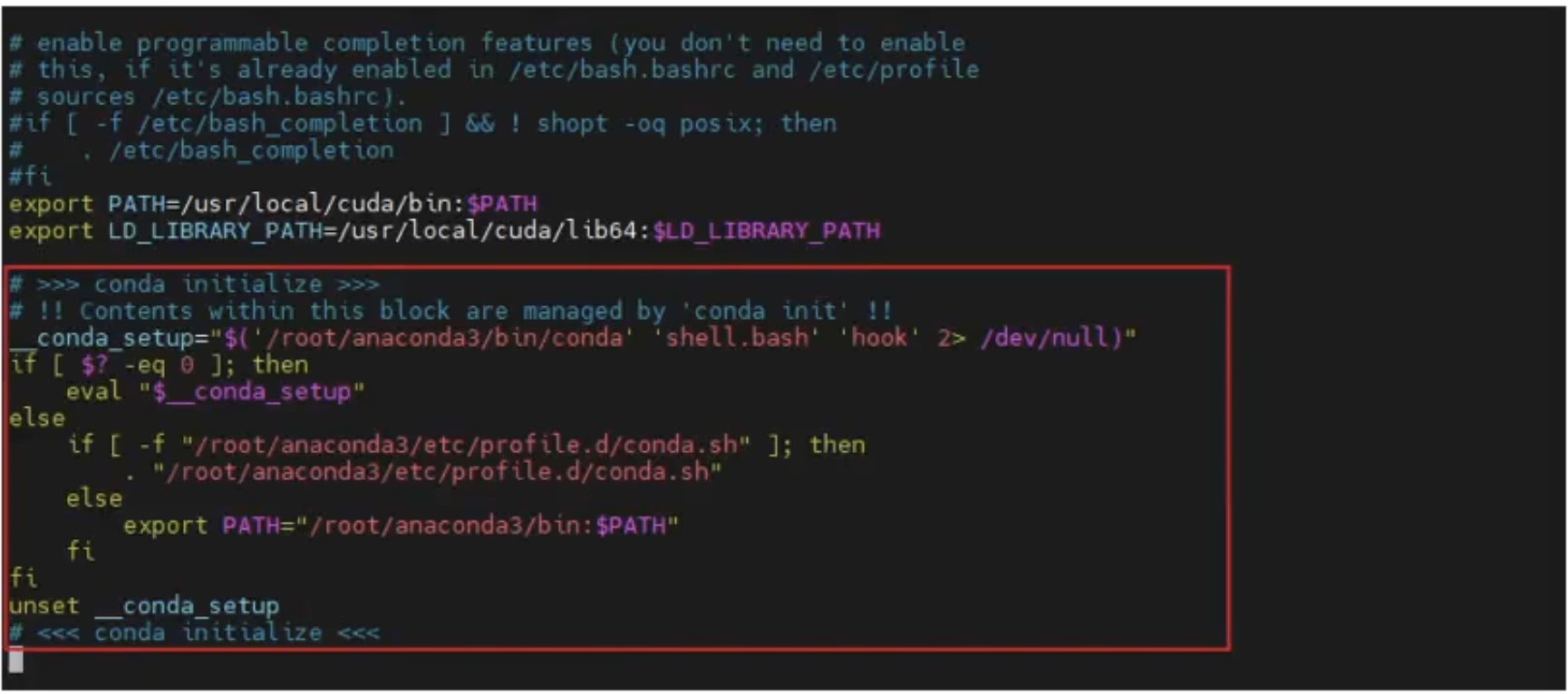
滚到文件的最后面。输入;进入插入模式,添加以下内容:
#>>> conda initialize >>
# !! Contents within this block are managed by 'conda init' !!
conda_setup="$('/root/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [$2-eq 0]; then
eval "$__conda_setup"
else
if [-f "/root/anaconda3/etc/profile.d/conda.sh"]; then
."/root/anaconda3/etc/profile.d/conda.sh"
else
export PATH="/root/anaconda3/bin: $PATH"
fi
fi
unset_conda_setup
# <<< conda initialize <<<
添加后,保存退出即可
第二步:退出重新连接下服务器即可
3. 模型部署
第一步:构建Python虚拟环境(隔离各个环境)
#创建虚拟环境
conda create --name chatglm python=3.10
#进入虚拟环境
conda activate chatglm
#如果需要离开此虚拟环境,可执行以下命令:离开当前虚拟环境「无需执行,因为后续的操作都是基于这个虚拟环境]
conda deactivate
第二步:下载chatglm-6b模型(知识库)
#创建目录:创建一个用于放置大模型项目相关内容的目录
mkdir -p /export/data/glm
#切换目录
cd /export/data/glm
#安装 国内模型资源平台
pip install -U huggingface_hub
#设置模型资源地址
export HF_ENDPOINT=https://hf-mirror.com
#下载对应模型内容(以下为一行)
huggingface-cli download --resume-download THUDM/chatglm-6b-int4 --local-dir THUDM/chatglm-6b-int4

第三步:上传ChatGLM-6B代码
cd /export/data/glm
#直接上传到此目录下
上传到 /export/data/glm
第四步:安装依赖
cd /export/data/glm/ChatGLM-6B
pip install -r requirements.txt -i https://mirror.sjtu.edu.cn/pypi/web/simple
第五步:修改代码。
在项目中,部分的依赖资源可能由于我们项目放置路径问题,导致部分资源存在加载不上的问题,一般会和开发小伙伴沟通,确认资源放置位置,从而进行修改调整
修改api.py文件中的模型位置:
cd /export/data/glm/ChatGLM-6B
vi api.py
#增加一行内容
model_path = "/export/data/glm/THUDM/chatglm-6b-int4"
#修改部分参数
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path,trust_remote_code=True).half().cuda()
model = model.eval()
第六步:运行api.py
启动后,即可打开大模型调用接口,交由开发人员通过接口调用大模型即可使用
安装额外依赖:
pip install fastapi uvicorn
默认部署在本地的8000端口,通过 POST 方法进行调用
curl -X POST "http://127.0.0.1:8000" -H 'Content-Type:application/json' -d '{"prompt":"你好","history":[]}'
得到的返回值为