day08 ELK
ElasticSearch + Logstash + Kibana 的合并简称。
一、ElasticSearch简介
1. 是什么?
简称ES,分布式搜索引擎(常见于baidu搜索,google搜索等),底层Lucene;
思考几个问题?
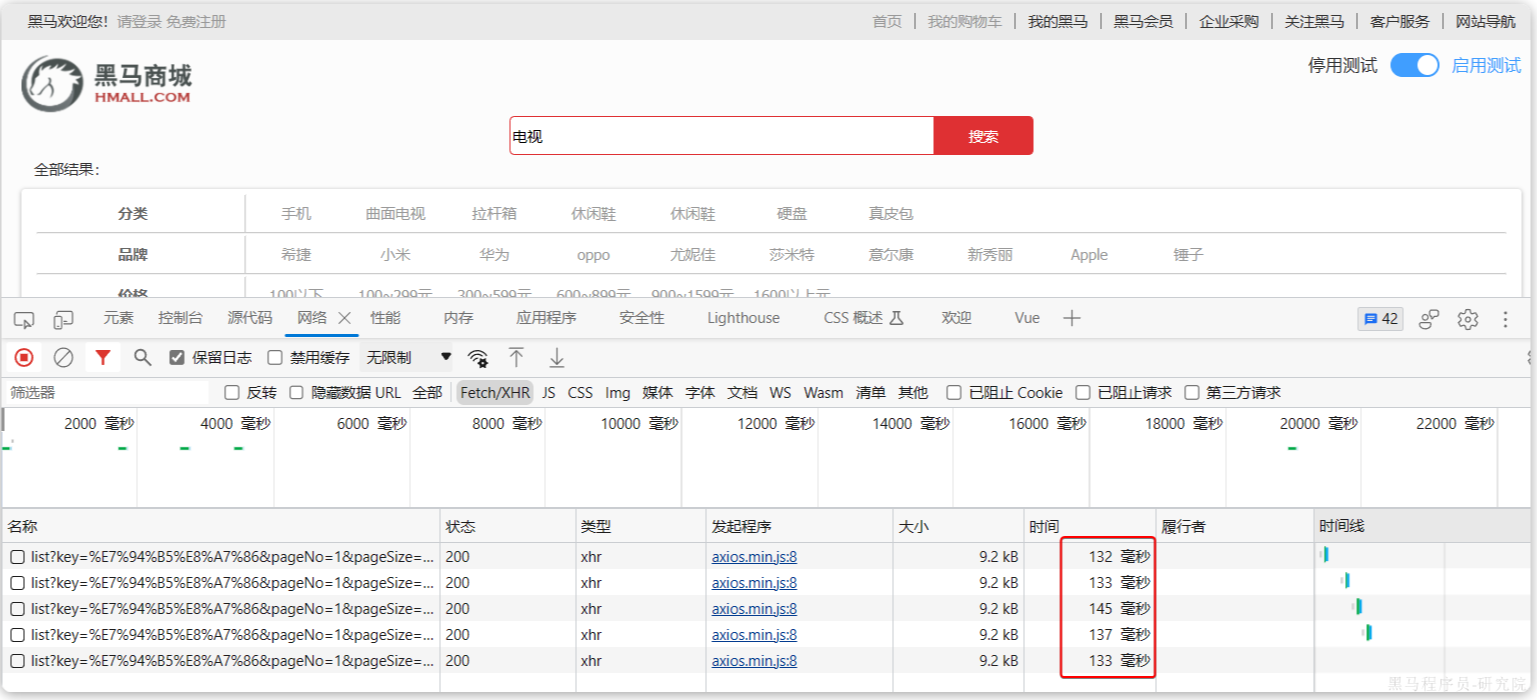
- 为什么baidu搜索很快?
- 我们mysql使用模糊搜索,为什么很慢? like %java培训%, 去千万级别的数据量中搜索,速度0.3s左右的耗时
- 如果是一篇文章?如果我的数据库的某个字段是存的小说章节内容。也不多,就1亿本小说。我去搜索小说内容关键字。如果单纯用mysql去做速度很慢。
- 数据库搜索,想要渲染,你搜到的那一句话,并且高亮显示,mysql只能显示,你命中的整行数据,而不是具体内部的数据。
2. 可以做什么?
可以实现,任意的类型数据的 近乎 实时的查询和分析功能。
任意数据类型:不管这个数据有没有结构,数字,还是地理位置等,ES都可以使用特定方案(倒排索引)来把他们进行排列,方便快速搜索。
ES支持无缝横向扩展(数据量实在太大,微博,每天50T数据内存redis 存储。),负载均衡思路。
3.有什么效果?
ES可以实现下列的效果:
- 高亮显示,命中的关键字
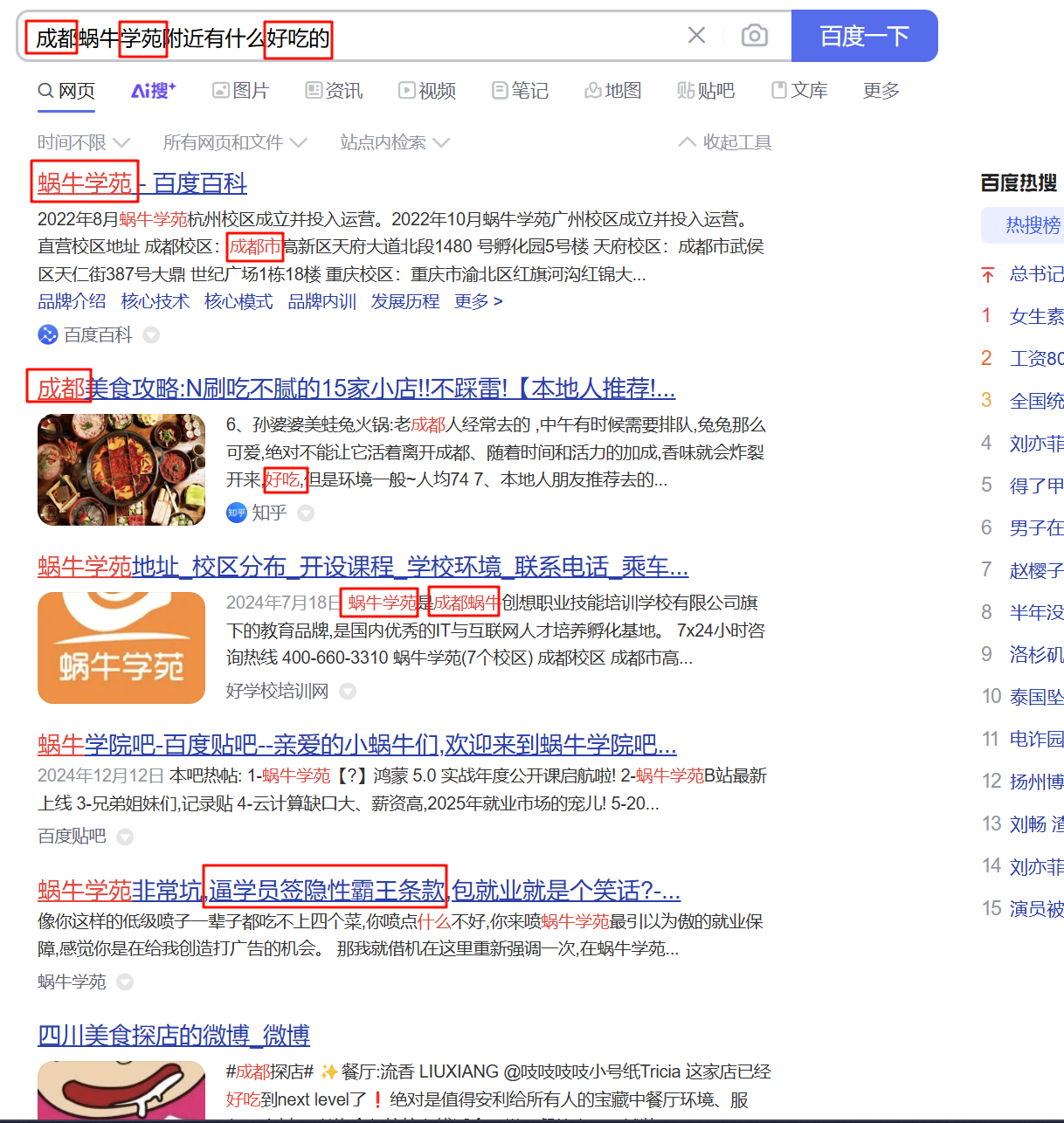
- 分词:中文分词,搜索引擎肯定是需要分词才行,不能拿着整句话去搜索
- 相关性排名:成都 蜗牛学苑 好吃的 权重很高的内容。 可以拿来赚钱(花钱买关键字权重)
- 我们会带着大家去了解权重,提高搜索分数,分数越高,越靠前。
4. 介绍名词
分词器
分词器的效果,IK中文分词器后面用。
引入依赖
<dependencies>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers</artifactId>
<version>3.6.2</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>7.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.3.1</version>
</dependency>
<!-- 中文分词器,升级后看看效果 -->
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
代码
package com.woniuxy;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.StringReader;
/**
* @Author: 马宇航
* @Todo: TODO
* @DateTime: 25/04/11/星期五 11:56
* @Component: 成都蜗牛学苑
**/
public class MyMain {
// 英文分词器:
// 输入字符串-->分割字符串-->去除停用词 a an the
private Analyzer a1 = new StandardAnalyzer();
// 简单分词器 直接使用 空格来分词
private Analyzer a2 = new SimpleAnalyzer();
// 中文分词器(词库分词) 的 停用词
private Analyzer a3 = new IKAnalyzer();
private String text = "What a beautiful China, what a beautiful world.";
private String text1 = "成都蜗牛学苑附近有什么好吃的";
@Test
public void test() throws Exception {
analyzer(a3, text1);
}
private void analyzer(Analyzer analyzer, String text) throws Exception {
// 在这里,第一个参数没有实际作用
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text));
// 获取每个单词信息
CharTermAttribute attribute = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while(tokenStream.incrementToken()) {
System.out.println(attribute);
}
tokenStream.end();
tokenStream.close();
}
}
文档
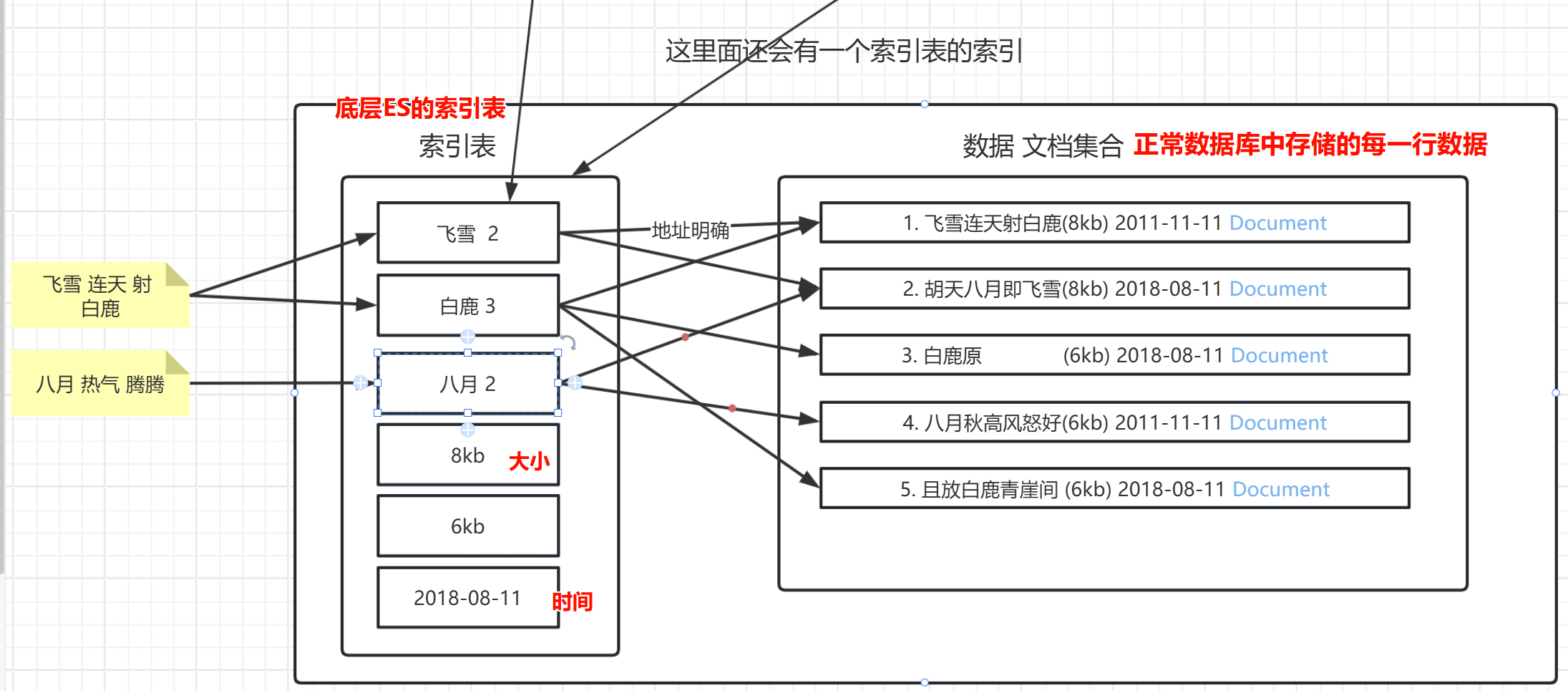
所有可以被搜索的数据,或者可以被创建为索引的数据,搜索引擎里面的一个名词,对应的就是某种数据结构。
doc1 1kb time:
飞雪连天射白鹿,笑书神侠倚碧鸳
doc2 1kb time:
北风卷地白草折,胡天八月即飞雪
正向索引
搜索 飞雪: 可以命中上面的2个文档。
mysql数据里面,全文检索(无法命中索引),从第一行,到最后一行,逐个比较。同时,也会对这些doc进行分词操作,和数据查询优化。
飞雪 doc1 和2 ,那么就会返回这两个文档数据。
但是当你的数据量达到PB级别,我搜索一个词,如果是正向,无法命中索引的话,逐行比较。很耗时。
倒排索引
ES底层就是使用的倒排索引。
倒排:索引是分词后的词,反向去找对应的文章
正向:通过文章去检索,再去找里面的词,能否匹配
全文检索
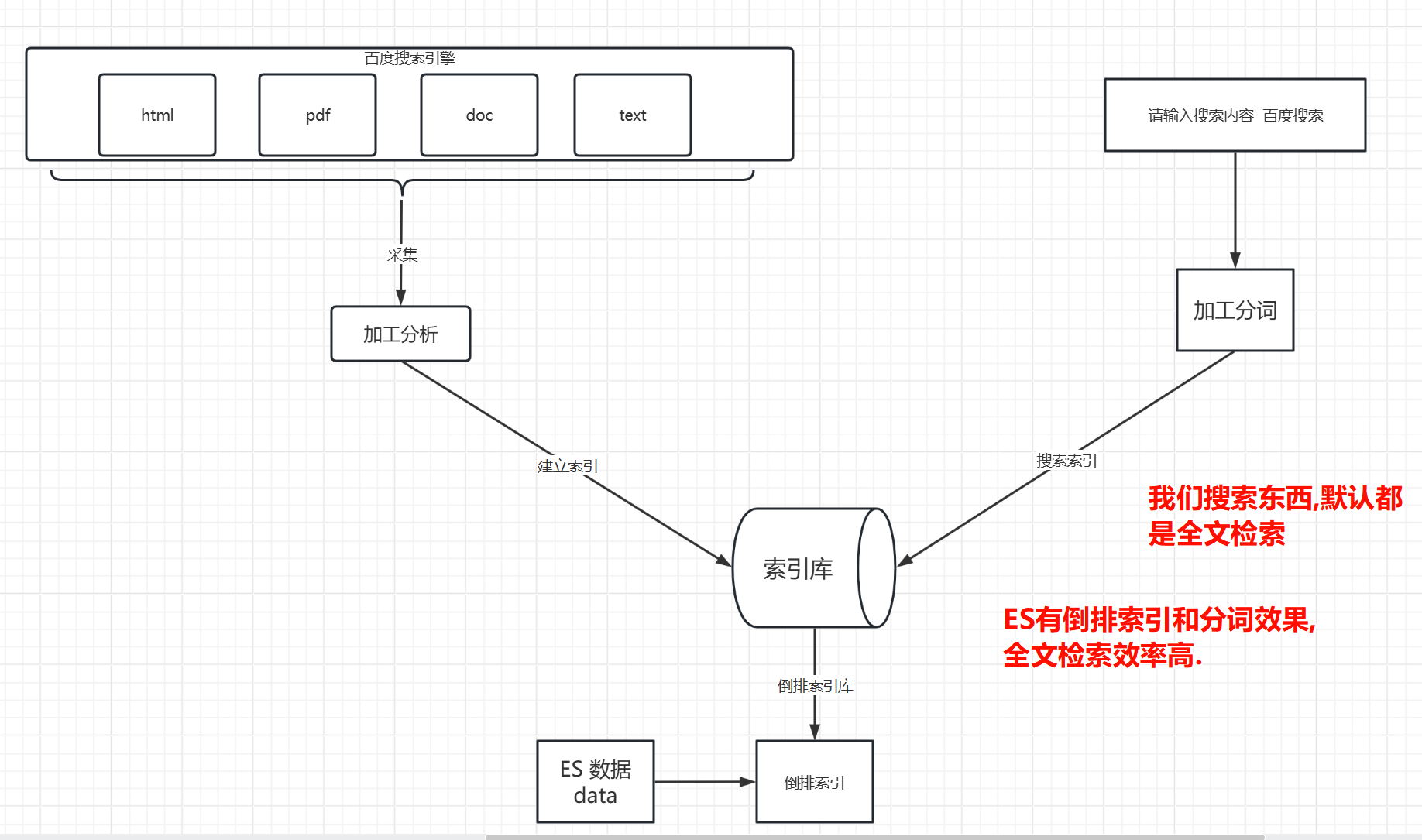
Baidu搜索,都是用的全文检索,ES的全文检索,就需要靠分词和倒排来快速全文检索。
但是和之前讲的mysql的(没命中索引的全文检索)全文检索不一样(从头开始一行一行匹配)
ES(Elasticsearch)中的全文检索(Full-Text Search)是一种技术,用于在大量文本数据中快速查找和检索相关信息。它不仅仅是对关键字进行简单的匹配,而是通过复杂的算法和索引机制,实现对文本内容的深度分析和高效查询。
全文检索的主要特点:
分词处理:
- 将文本内容拆分成多个词汇(Token),以便更精确地进行匹配。
- 例如,”Elasticsearch 是一个搜索引擎”会被分词为”Elasticsearch”、”是”、”一个”、”搜索引擎”。
索引构建:
- 通过分词后的词汇构建索引,索引是全文检索高效查询的基础。
- 索引可以理解为一种数据结构,用于快速定位包含特定词汇的文档。
相关性排序:
- 查询结果会根据与查询条件的相关性进行排序,最相关的结果排在前面。
- 相关性计算通常考虑词汇频率(TF)、逆文档频率(IDF)等因素。
模糊匹配:
- 支持模糊查询,即使输入的查询词与文档中的词汇不完全一致,也能找到相关结果。
- 例如,拼写错误、同义词匹配等。
多字段检索:
- 可以在多个字段中进行检索,如标题、正文、作者等。
- 支持对不同字段赋予不同的权重,以影响相关性排序。
应用场景:
- 搜索引擎:如网站内部的搜索功能,快速找到相关内容。
- 日志分析:在大量日志数据中检索特定事件或错误信息。
- 数据分析:在文本数据中进行复杂查询和分析。
例子:
假设有一个文档集合,包含以下文档:
- “Elasticsearch 是一个基于 Lucene 的分布式搜索引擎。”
- “Lucene 是一个高性能的全文检索库。”
- “搜索引擎可以提高网站的可用性。”
当用户查询”搜索引擎”时,全文检索系统会返回包含”搜索引擎”这个词的文档,并根据相关性进行排序,可能的结果如下:
- “Elasticsearch 是一个基于 Lucene 的分布式搜索引擎。”(相关性最高)
- “搜索引擎可以提高网站的可用性。”(相关性次高)
通过全文检索,用户可以快速找到最相关的信息,提高信息检索的效率和准确性。
相关性得分
搜索的某句话,在某篇文章中出现的次数很多,分数就越高。
匹配的文字越全,完全一样,相关性得分也会更高。
给钱越多,相关性得分越高,即使你网页或者文章中,完全没有这个字!
二、安装、启动
es比较吃内存,所以我建议大家为即将安装es的虚拟机设置大一点的内存,将来在安装好es以后,也就可以随时调整es内置的jvm的内存大小了。(-Xms2g -Xmx2g)
| 软件 | 下载地址 |
|---|---|
| ElasticSearch | https://www.elastic.co/cn/start |
| Kibana | https://www.elastic.co/cn/start |
| Logstash | https://www.elastic.co/cn/downloads/logstash |
2.1 创建账户
es要求必须以非root账户启动服务,所以我们创建以下账户
adduser woniu
passwd woniu
2.2 上传es
scp elasticsearch-8.17.0-linux-x86_64.tar.gz root@192.168.206.128:/usr/local
scp kibana-8.17.0-linux-x86_64.tar.gz root@192.168.206.128:/usr/local
#上面的命令,支持目录传递
root@192.168.206.128's password:
elasticsearch-8.17.0-linux-x86_64.tar.gz 100% 607MB 161.4MB/s 00:03
以root账号上传elasticsearch-8.17.0-linux-x86_64.tar.gz到/usr/local目录下
进入/usr/local目录下:解压
tar -zxvf elasticsearch-8.17.0-linux-x86_64.tar.gz授予woniu用户权限
chown -R woniu /usr/local/elasticsearch-8.17.0/
2.3 启动es服务
为了让es服务能够被指定机器访问,在es根目录下的config目录下,修改es配置文件elasticsearch.yml:(注意改之前,先备份一下)
备份:
cp /usr/local/elasticsearch-8.17.0/config/elasticsearch.yml /usr/local/elasticsearch-8.17.0/config/elasticsearch.yml.back
编辑:
vim /usr/local/elasticsearch-8.17.0/config/elasticsearch.yml
使用v进入可视模式,按G2下,选中所有内容,按dd清空所有内容,复制下列内容,粘贴后,按ESC退出编辑后,使用:wq保存即可。ggVG –>dd 就可以全部删掉
注意,复制进去会缺前两个字母,还有注释会多几行
luster.name: my-application
node.name: node-1
# 允许任何机器链接当前es服务
network.host: 0.0.0.0
http.port: 9200
# 有成为主节点资格的节点列表
# 127.0.0.1和[::1]都代表本机
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
cluster.initial_master_nodes: ["node-1"]
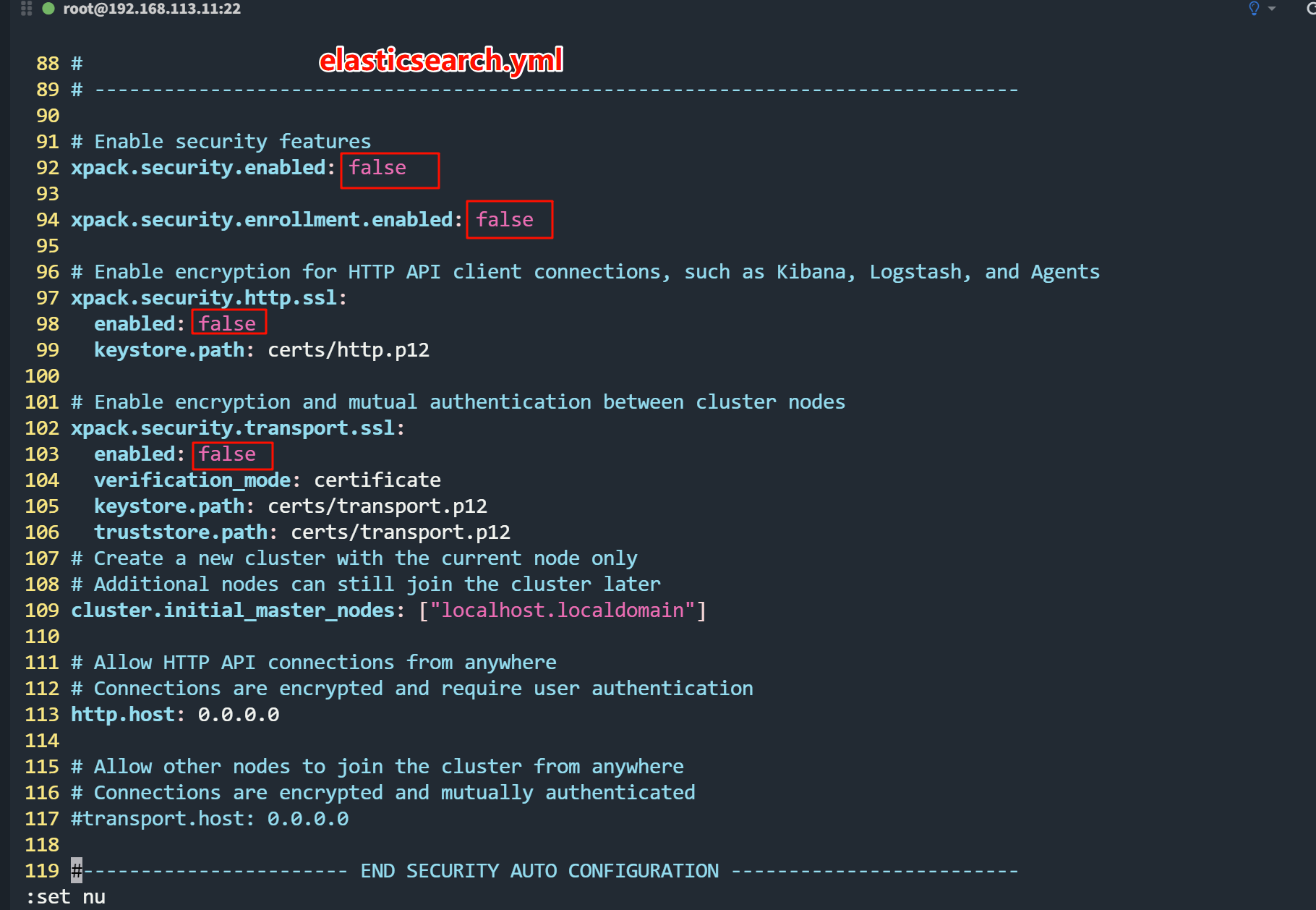
如下图,关闭认证和ssl这种访问方式,我们本地就直接使用http的方式去访问。
(跳过)
修改/etc/security/limits.conf,设置系统最大线程个数(否则启动es服务时会报错:max number of threads [2988] for user [elk] is too low, increase to at least [4096]),在该配置文件的末尾追加以下内容:
* soft nofile 65535
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
修改/etc/sysctl.conf(否则启动es服务时会报错:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]),在该配置文件的末尾追加以下内容:
vm.max_map_count=262144
为了加载这个修改,再执行以下命令:
sysctl -p
es服务默认占用9200端口,所以我们要开放9200端口(主要要使用root用户执行以下命令):
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --reload
使用su woniu即可切换用户woniu
su woniu
使用woniu用户,进入之前解压后的es目录中,启动es服务
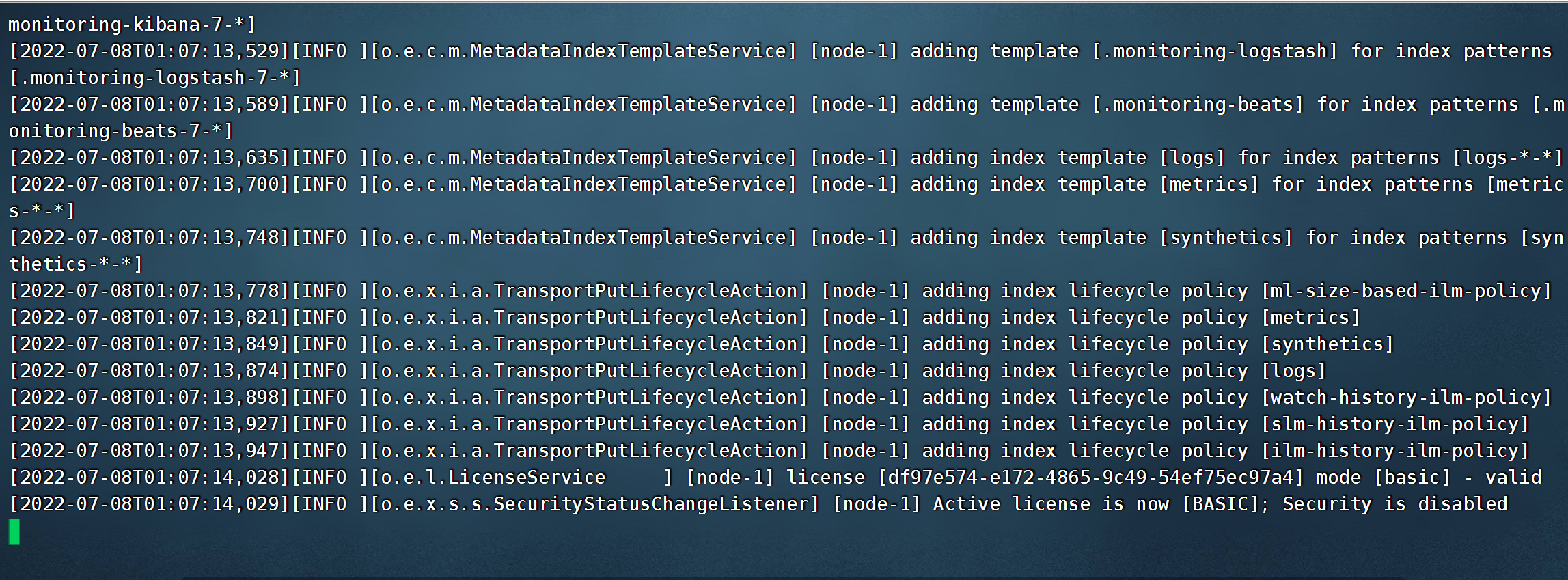
./bin/elasticsearch
出现下列内容则表示启动成功:
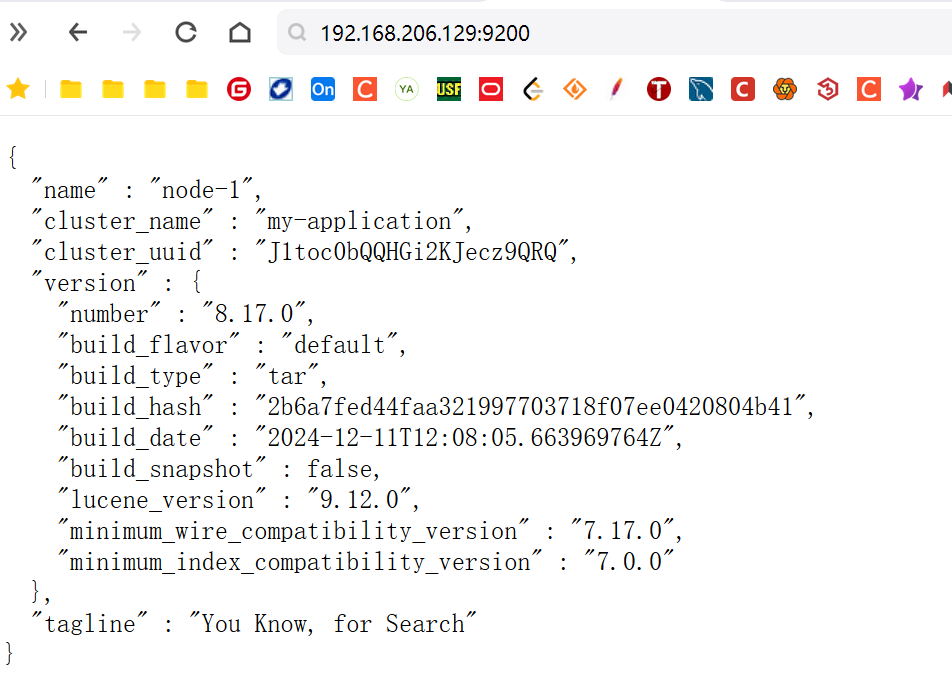
回到win访问请求:
另外,如果不小心以root用户启动了es服务,那么服务肯定会启动失败的,更重要的是,在es的logs文件夹下也会产生本次启动失败的日志文件,这些日志文件的owner是root,这就导致,就算我们再以elk用户来启动es服务时,仍然会出现“没有权限”的提示,尽管这并不影响es服务的启动。所以每当我们不小心用root启动es服务之后,都应该删掉那些owner为root的日志文件。
如果想要配置https凭证,则需要在elasticsearch.yml追加;
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
xpack.security.http.ssl:
enabled: false
keystore.path: certs/http.p12
xpack.security.transport.ssl:
enabled: false
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
2.4 启动Kibana
切换到root用户
su root
将kibana-8.17.0-linux-x86_64.tar.gz上传到woniu账户的家目录下
进入/usr/local目录,解压
tar -zxvf kibana-8.17.0-linux-x86_64.tar.gz
授权
chown -R woniu kibana-8.17.0-linux-x86_64
修改Kibana的配置文件config/kibana.yml,可用以下内容直接替换该配置文件中的内容:(注意备份)
server.port: 5601 # kibana端口
server.host: "0.0.0.0" # 允许任意远程机器连接kibana
elasticsearch.hosts: ["http://127.0.0.1:9200"] # kibana要连接的es服务的url
elasticsearch.requestTimeout: 60000 # Kibana等待elasticsearch响应的最大时间
切换到elk,进入到Kibana的根目录,执行以下命令,以启动Kibana
su woniu
/usr/local/kibana-8.17.0-linux-x86_64/bin/kibana

出现这个表示启动成功:

复制个新窗口,默认切换到root,开放5601端口:
firewall-cmd --zone=public --add-port=5601/tcp --permanent
firewall-cmd --reload
点击Explore on my own:进入后点击dev-tools
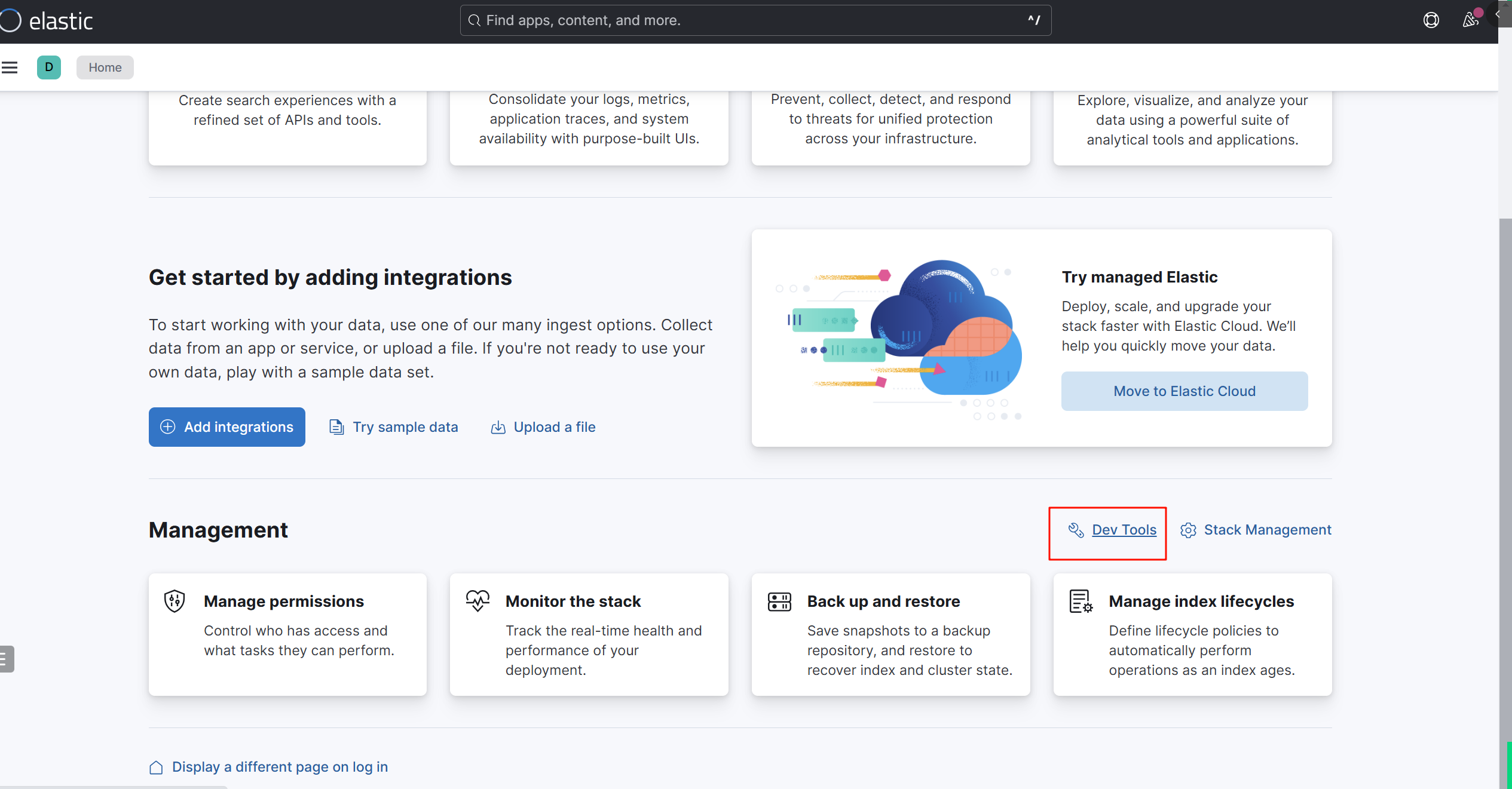
点击下图运行标记,出现下图,则表示环境全部搭建成功:
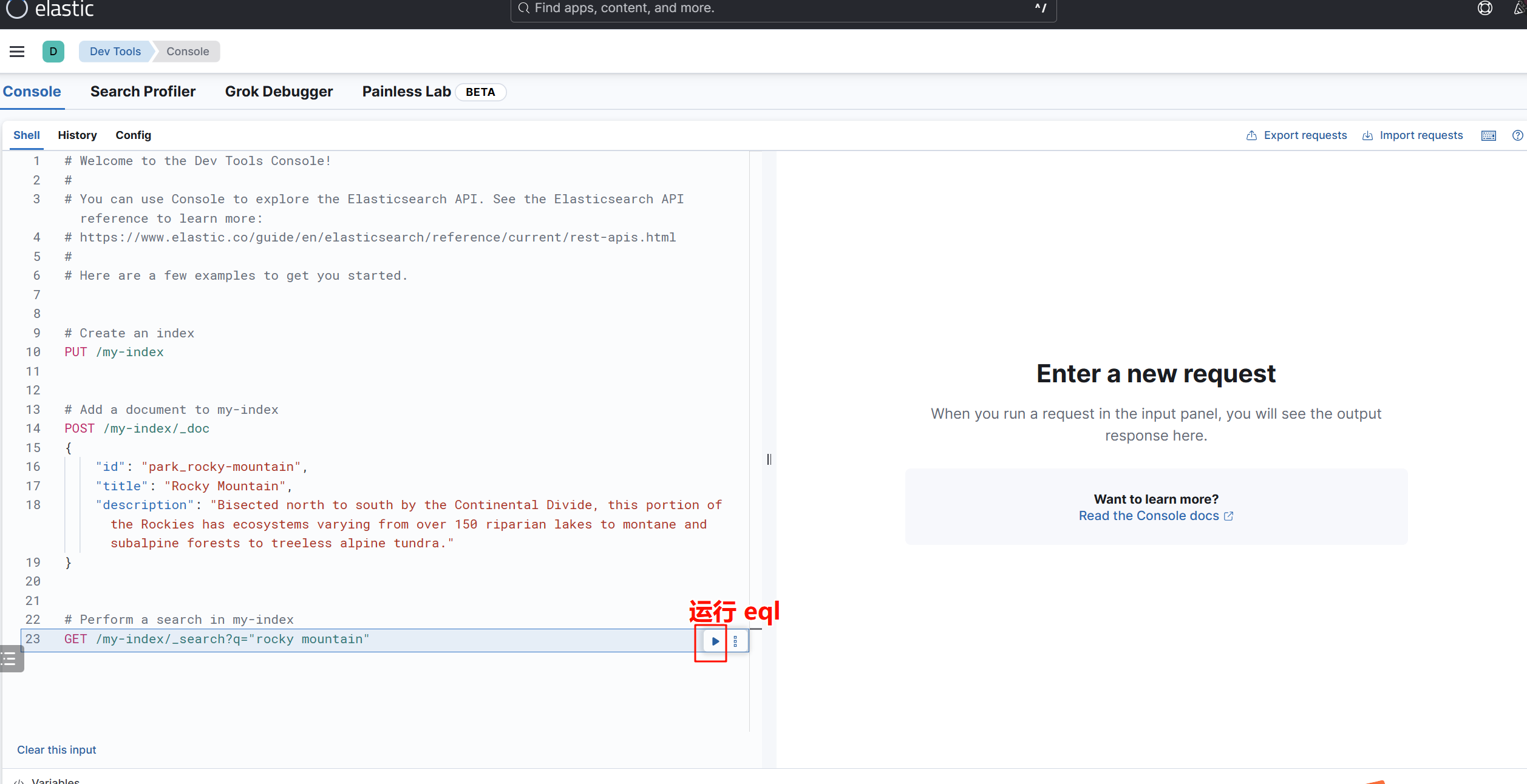
2.5 简单测试命令
查看所有节点 加v参数可查看列名信息。
GET /_cat/nodes?v
查看所有节点的健康情况
GET /_cat/health?v
查看主节点信息
GET /_cat/master?v
查看索引
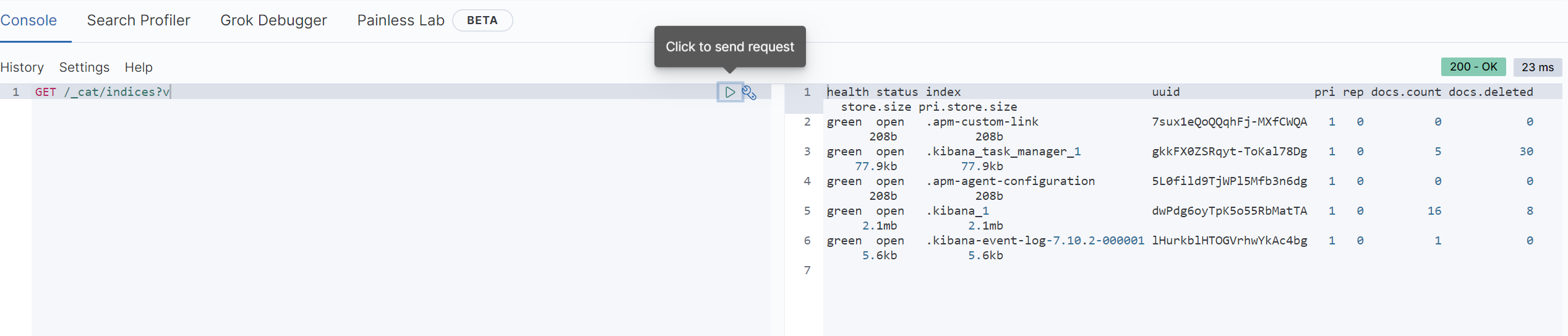
GET /_cat/indices?v
分词器体验:由于没有IK中文分词器,所以……
GET _analyze
{
"analyzer": "standard",
"text": "What a beautiful China, what a beautiful world."
}
GET _analyze
{
"analyzer": "standard",
"text": "我是蜗牛的马宇航老师"
}
三、上传json文件
导入我们想要的数据
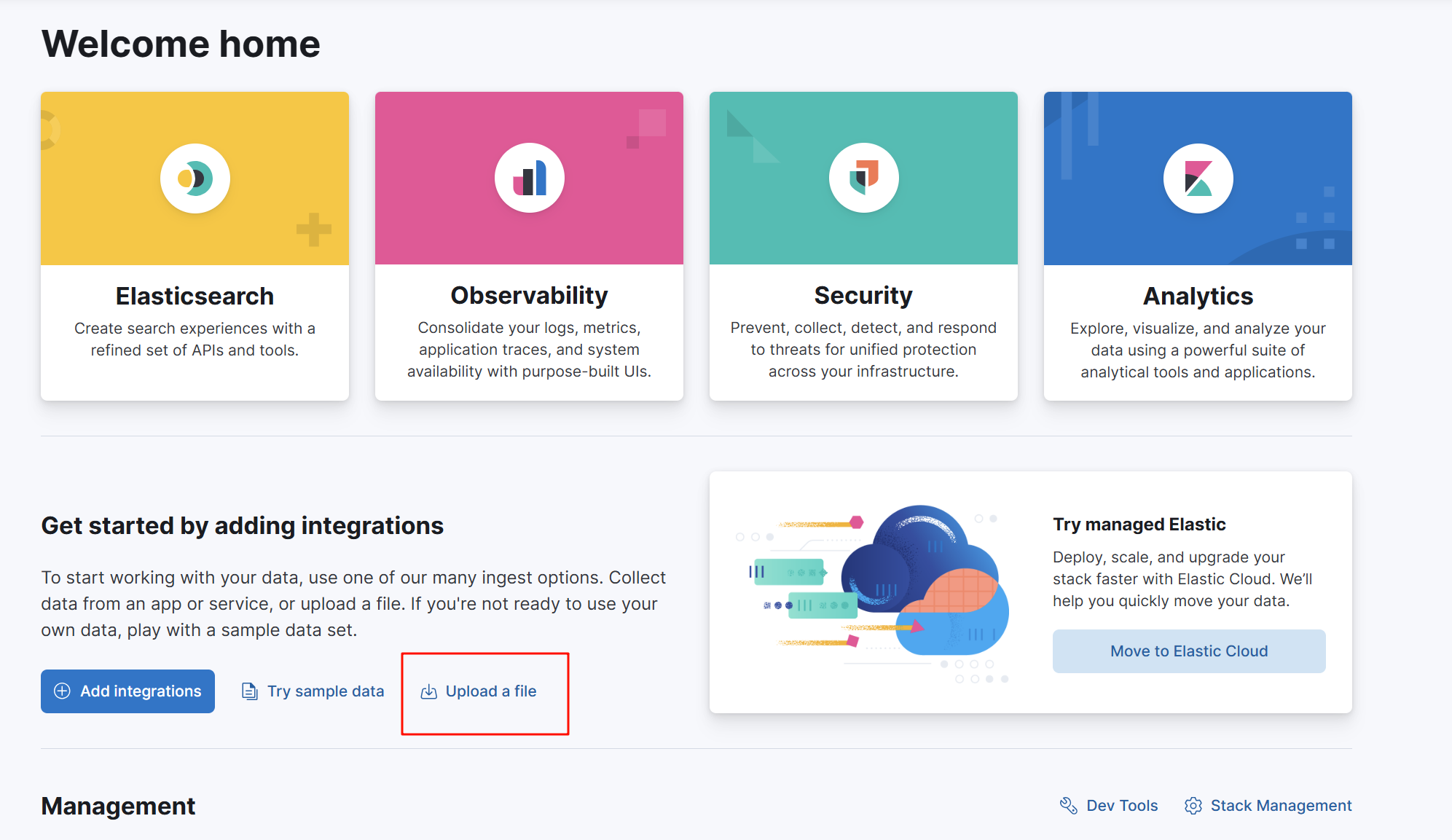
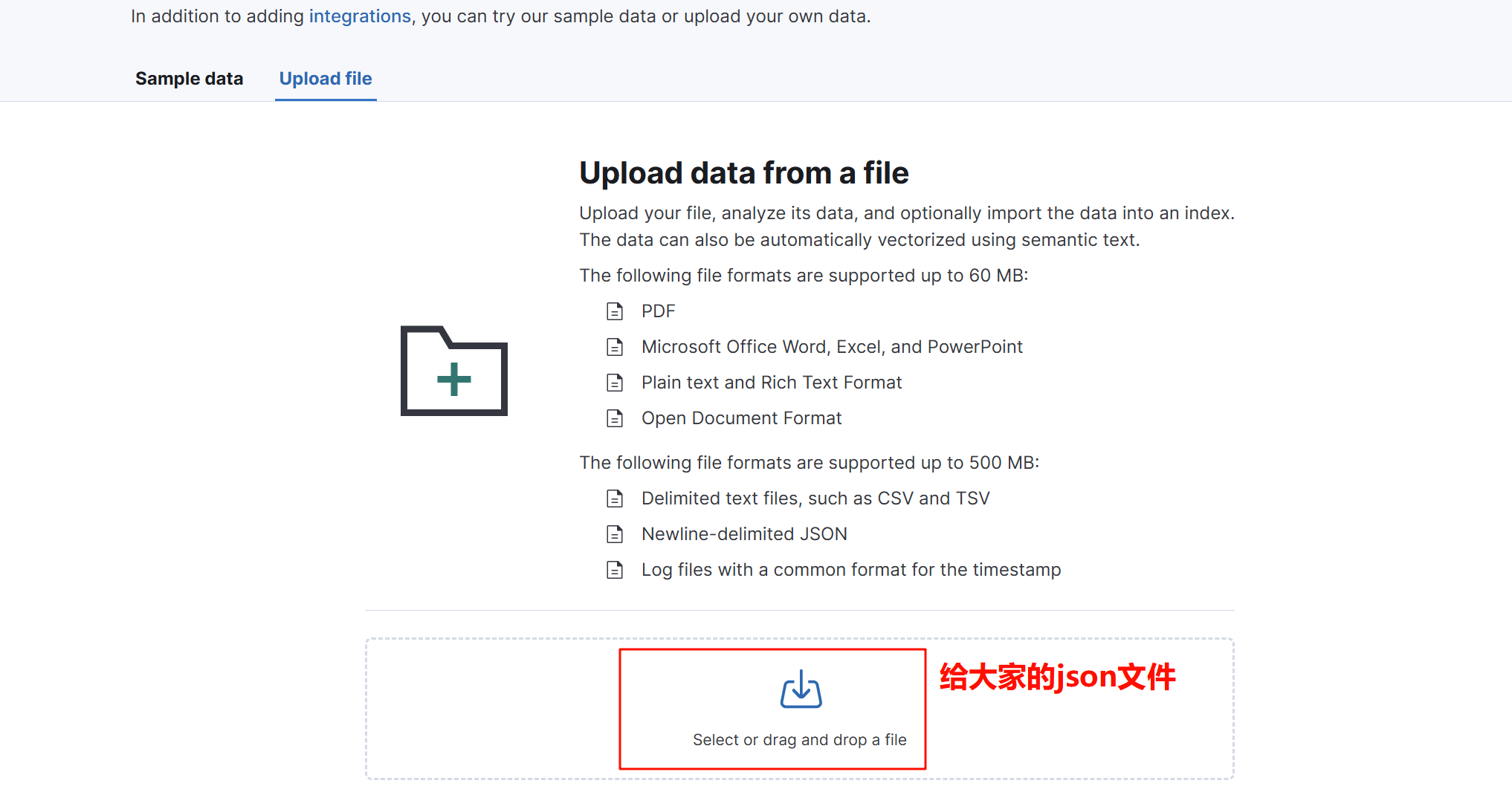
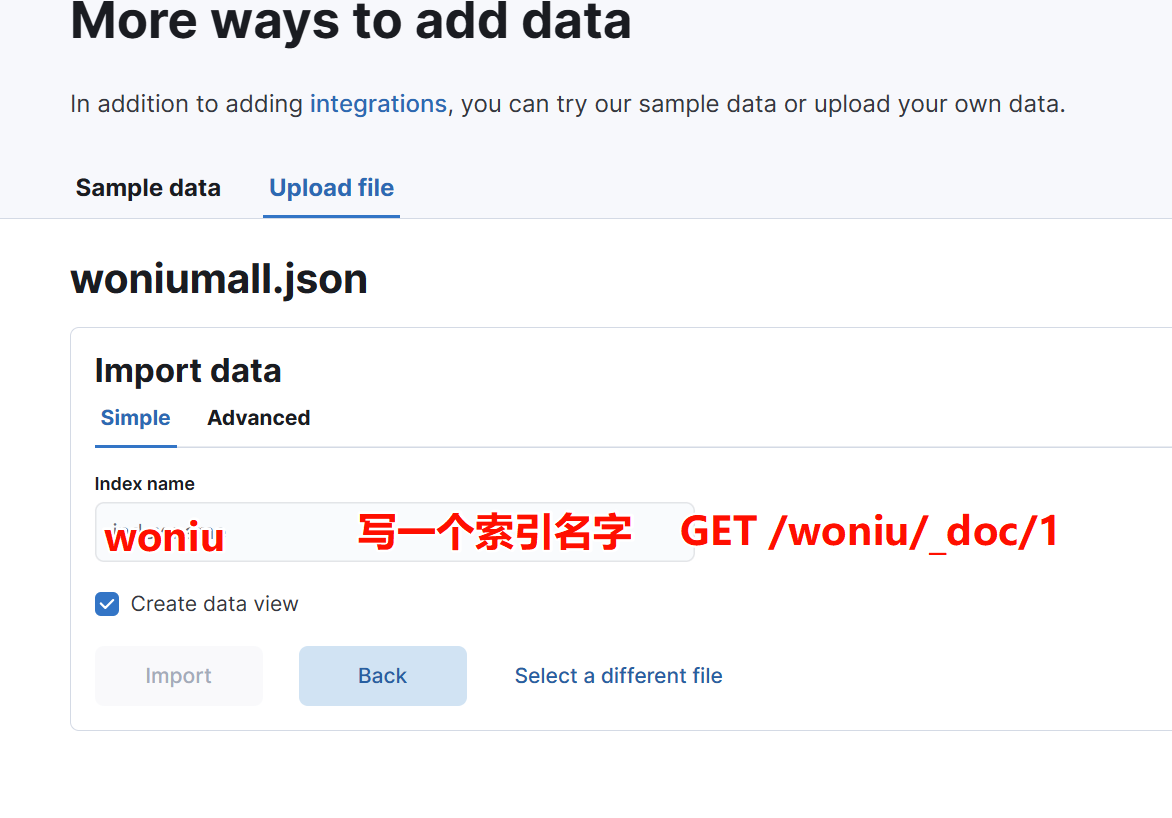
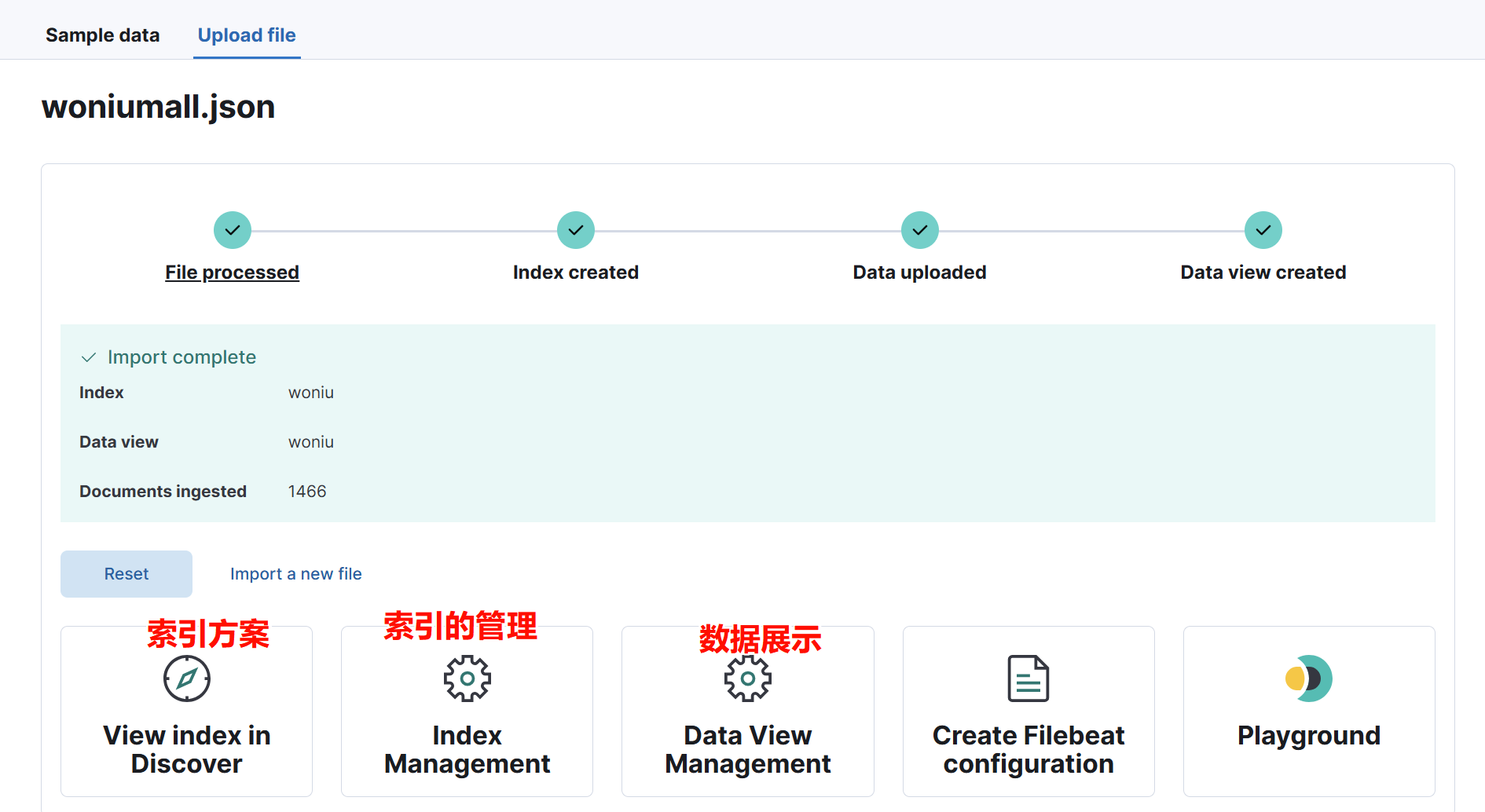
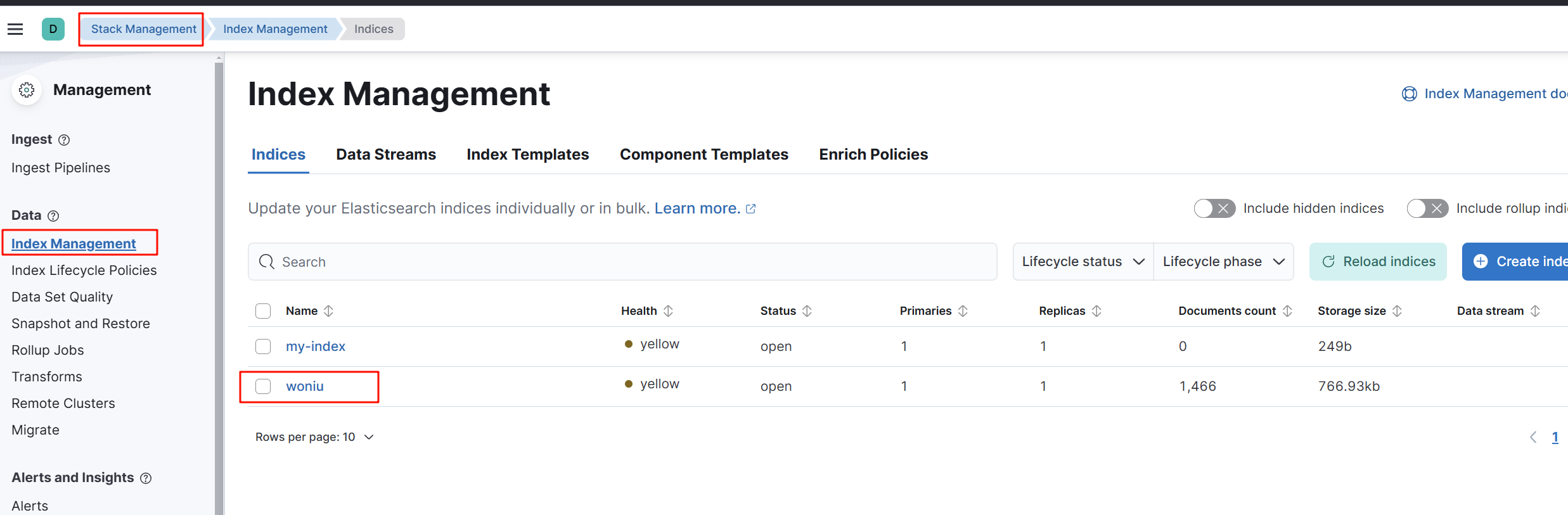
第一个索引方案
第二个索引管理
四、dev-tool(了解)
最终所有d操作,都是在Springboot中,就不用怎么学kql语法了。
同时,SpringBoot中操作ES很简单,JPA。就是JPA语法。
1 在dev控制台搜索索引数据
ES中支持2种搜索方法:
查询该索引下的所有数据:(了解)
GET woniumall/_search?q=*正常搜索功能:
GET woniumall/_search
{
"query": {
"match_all":{}
}
}
上述的搜索方法被称之为Query DSL(领域特定语言)。DSL是从第二行到第第六行结束,不包含GET woniumall/_search这个第一行。
2 排序
对salenums进行排序,也发现,对字符串不能进行排序。
GET woniumall/_search
{
"query": {
"match_all":{}
},
"sort": [
{
"salenums": {
"order": "desc"
}
}
]
}
3 分页
从第0页开始,每页5条数据。
GET woniumall/_search
{
"query": {
"match_all":{}
},
"from": 0,
"size": 5
}
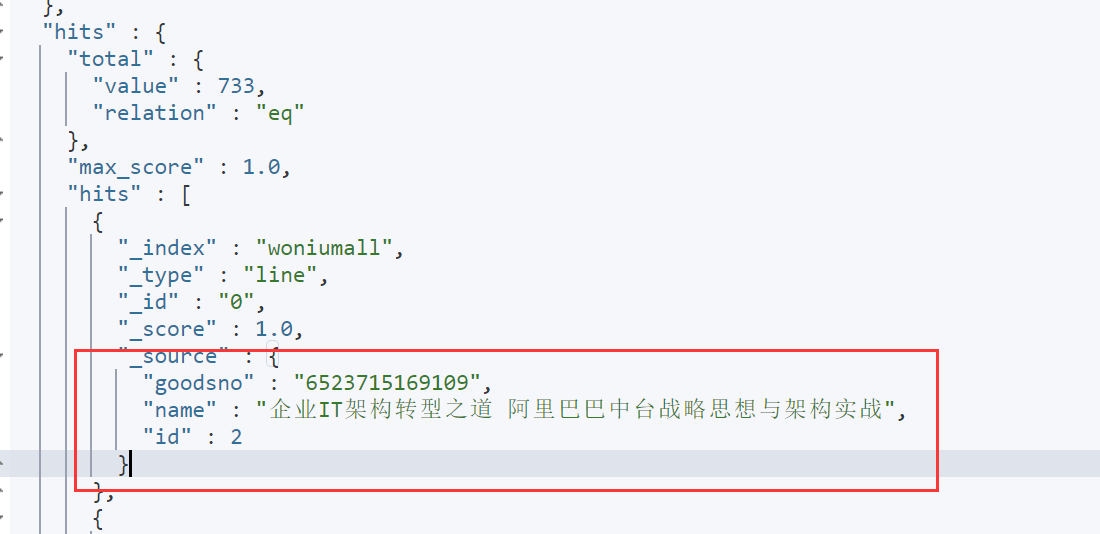
4 筛选字段
GET woniumall/_search
{
"query": {
"match_all":{}
},
"_source": ["id","name","goodsno"]
}
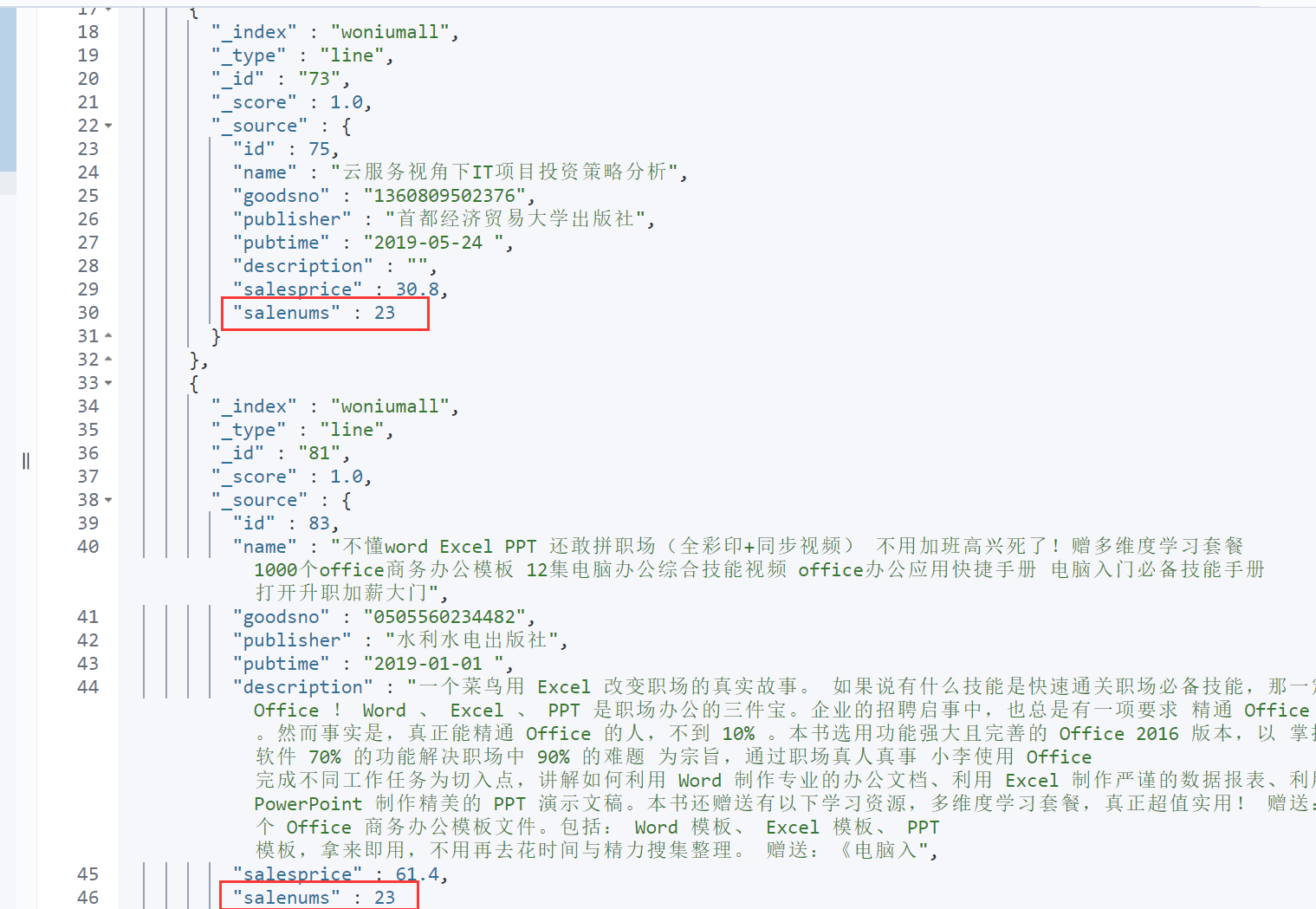
5 精准匹配
精准匹配:如果查询的是非字符串字段,则本次查询是精准匹配,不会涉及到分词操作。
GET woniumall/_search
{
"query": {
"match": {
"salenums": "23"
}
}
}
6 模糊匹配
查询字符串,则会分词,使用模糊匹配!而且会使用分词
GET woniumall/_search
{
"query": {
"match": {
"description": "本书为郭沫若晚年封笔之作"
}
}
}
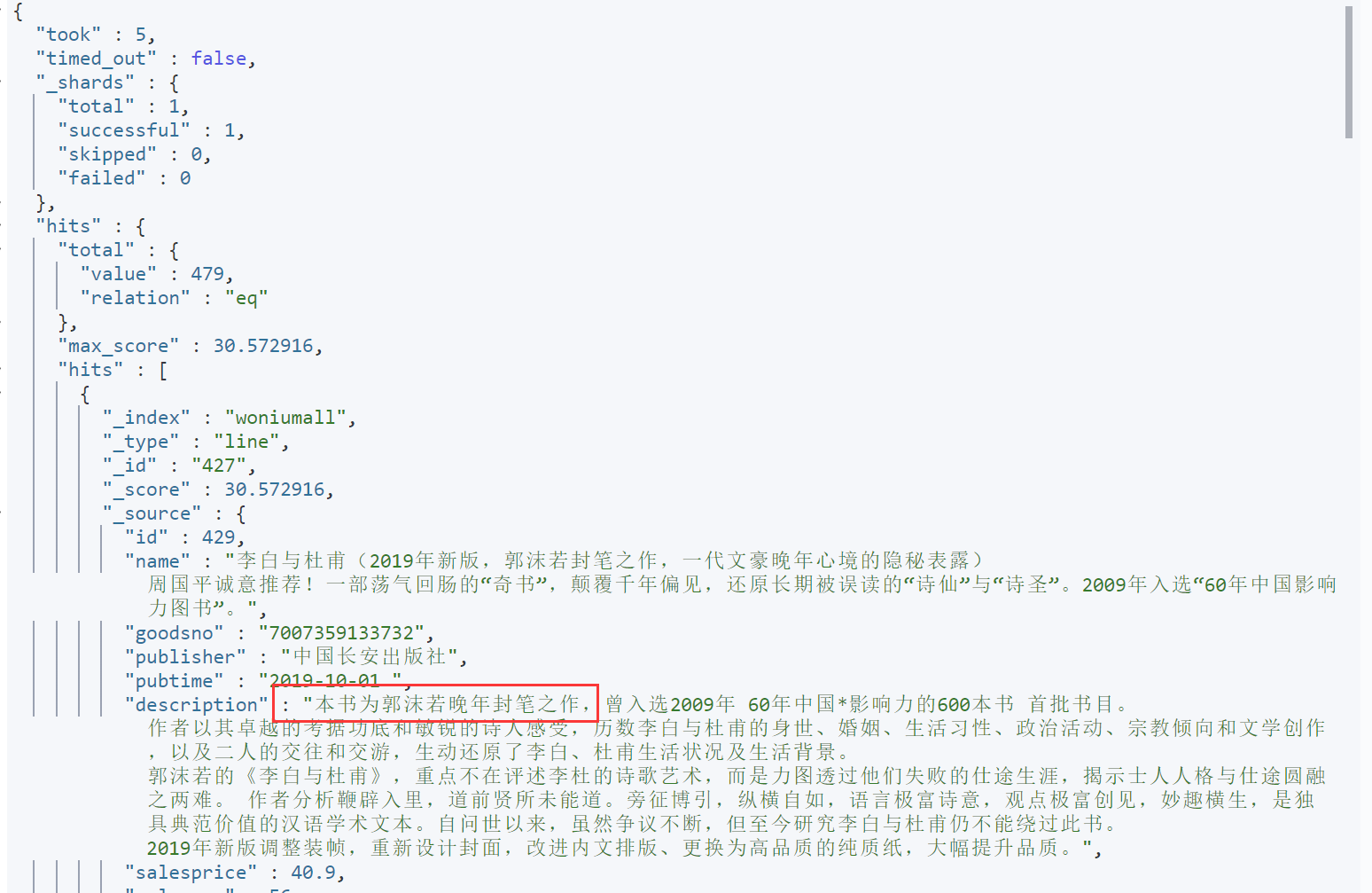
分词操作,会发生在两个时机:索引文档的时候,会对文档内容进行分词,创建的是倒排索引;在模糊匹配的时候,再对我们查询的条件文本内容进行分词,拿着搜索条件中的分词结果去匹配索引内容。而且这两个时机,他们所使用的分词器必须是一致的。
在使用含.keyword后缀的条件时,不会使用分词
搜索内容少一个字都不行。
GET woniumall/_search
{
"query": {
"match": {
"publisher.keyword": "中国长安出版社"
}
}
}
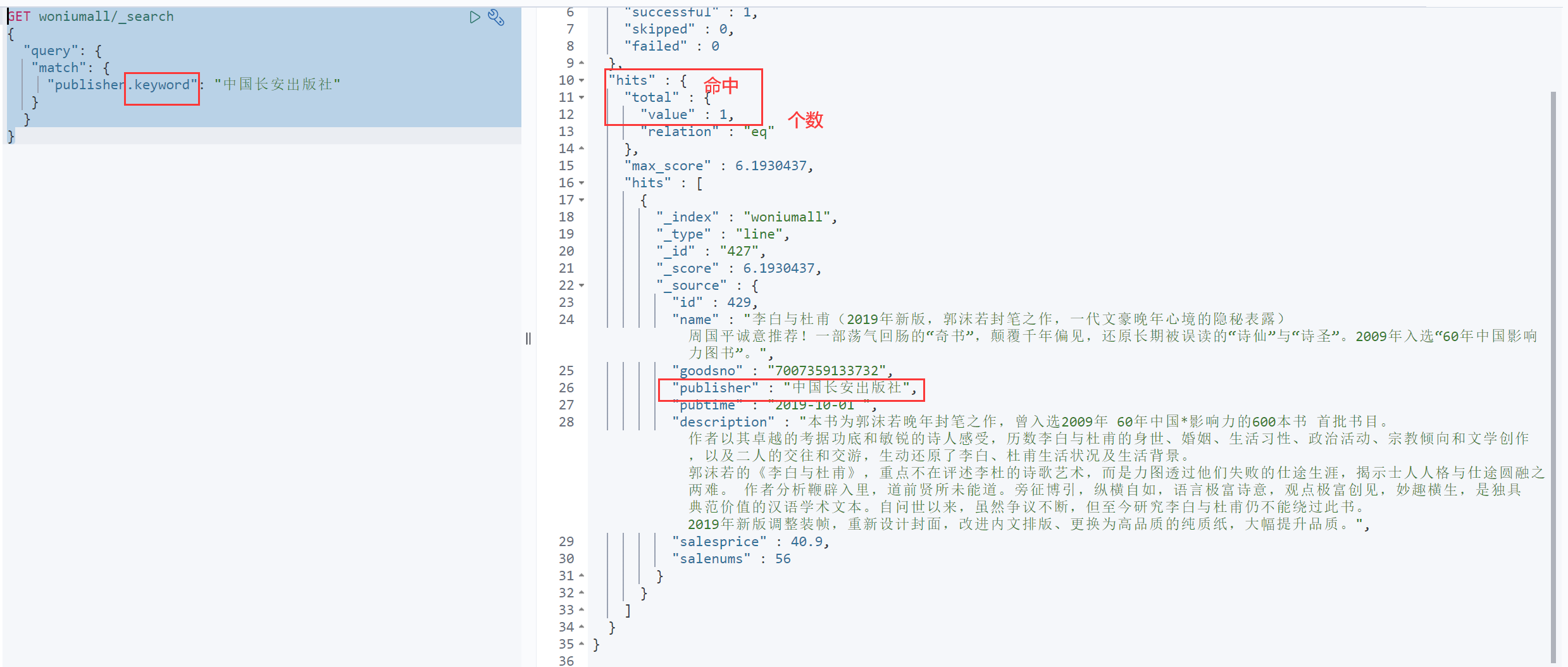
7 multi_match 多字段匹配
GET woniumall/_search
{
"query": {
"multi_match": {
"query": "李白 长安",
"fields": ["name","publisher"]
}
}
}
8 范围查询
GET woniumall/_search
{
"query": {
"range": {
"salesprice": {
"gte": 50,
"lte": 60
}
}
}
}
五、IK安装
IK分词器在是一款 基于词典和规则 的中文分词器。
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词器是将每个字看成一个词,比如”我爱技术”会被分为”我”,”爱”,”技”,”术”,这显然不符合要求,所以我们需要安装中文分词器IK来解决这个问题,所以这里就需要更加智能的分词器IK分词器了。
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
1 安装
在elasticsearch的plugins目录下创建名为ik的目录
mkdir ik将ik压缩包拷贝到ik目录下并解压,同时删除压缩包
unzip elasticsearch-analysis-ik-8.17.0.zip记得将权限附上
chown -R woniu ik否则在启动es服务的时候,总是会显示这个错误:java.io.FileNotFoundException: /usr/es/logs/my-application.log (权限不够)
重启elasticsearch
在客户端,输入以下内容
2 analyzer分词策略
GET _analyze
{
"analyzer": "ik_smart",
"text": ["我爱中国人"]
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["我爱中国人"]
}
分词策略主要有两种:ik_smart和ik_max_word
ik_smart:粒度较粗比较智能
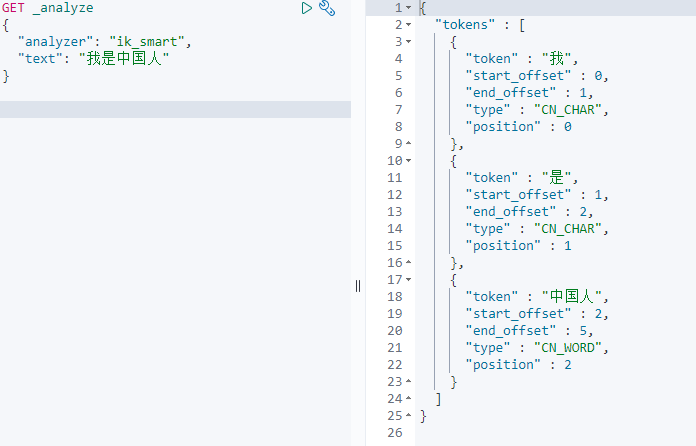
ik_max_word:最大限度分词。粒度较细
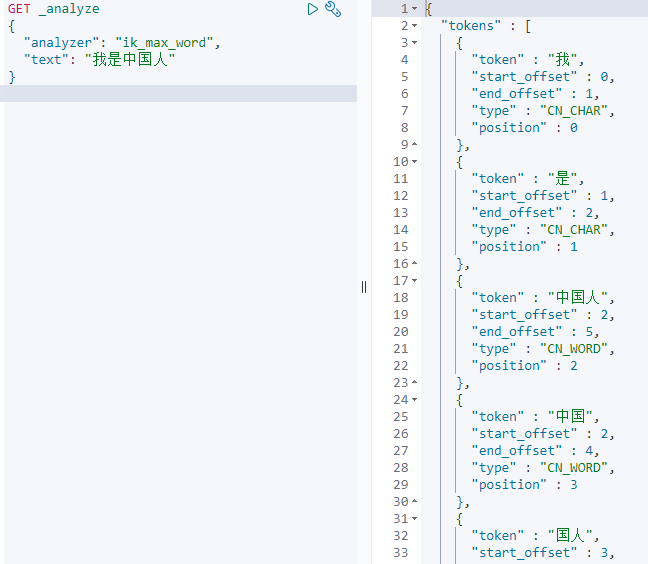
一般的策略是建立索引使用ik_max_word,查询时使用ik_smart,这样就能尽可能多的查到结果
3 删除woniumall,重新指定这个使用ik分词器当做索引
# DELETE woniumall
PUT woniumall
{
"settings":{
"index":{
"analysis.analyzer.default.type":"ik_max_word"
}
}
}
# 批量插入数据 --文件操作
PUT woniumall/_bulk
文章内容直接cv过来
3 配置自定义词典
1 在es目录下的plugins/ik/config下创建my.dic、
touch my.dic
2 修改IK配置文件IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3 检查下my.dic格式 确保是UTF-8
file -i my.dic
4 以woniu账号重启ES
5 远程词典配置
大致步骤:
在tomcat中,发布一个web应用,在该web应用中,发布一个文件:words.dic,内容如下:如果有多个词的话,则一个词占一行
访启动tomcat,访问地址为: http://192.168.1.100:8080/mydic/words.dic
修改ik分词器的配置:IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<entry key="ext_dict"></entry>
<entry key="ext_stopwords"></entry>
<entry key="remote_ext_dict">http://192.168.1.100:8080/mydic/words.dic</entry>
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>以woniu用户,重启es,然后再次进行测试
如果还有其他词语,添加在tomcat的words.dic中,不用重启es,等会即可。